Example
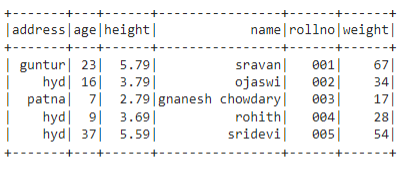
In this example, we will create the PySpark DataFrame with 5 rows and 6 columns and display it using the show() method.
import pyspark
# import SparkSession for creating a session
from pyspark.sql import SparkSession
# create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students = [
{'rollno': '001', 'name': 'sravan', 'age': 23,
'height': 5.79, 'weight': 67, 'address': 'guntur'},
{'rollno': '002', 'name': 'ojaswi', 'age': 16,
'height': 3.79, 'weight': 34, 'address': 'hyd'},
{'rollno': '003', 'name': 'gnanesh chowdary', 'age': 7,
'height': 2.79, 'weight': 17, 'address': 'patna'},
{'rollno': '004', 'name': 'rohith', 'age': 9,
'height': 3.69, 'weight': 28, 'address': 'hyd'},
{'rollno': '005', 'name': 'sridevi', 'age': 37,
'height': 5.59, 'weight': 54, 'address': 'hyd'}]
# create the dataframe
df = spark_app.createDataFrame(students)
# display dataframe
df.show()
Output:
PySpark – concat()
concat() will join two or more columns in the given PySpark DataFrame and add these values into a new column.
By using the select() method, we can view the column concatenated, and by using an alias() method, we can name the concatenated column.
Syntax
where,
- dataframe is the input PySpark Dataframe
- concat() – It will take multiple columns to be concatenated – column will be represented by using dataframe.column
- new_column is the column name for the concatenated column.
Example 1
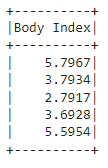
In this example, we will concatenate height and weight columns into a new column and name the column as Body Index. Finally, we will only select this column and display the DataFrame using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import concat function
from pyspark.sql.functions import concat
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# concatenating height and weight into a new column named - "Body Index"
df.select(concat(df.height,df.weight).alias("Body Index")).show()
Output:
Example 2
In this example, we will concatenate rollno, name, and address columns into a new column and name the column as Details. Finally, we will only select this column and display the DataFrame using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import concat function
from pyspark.sql.functions import concat
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# concatenating rollno , name and address into a new column named - "Details"
df.select(concat(df.rollno,df.name,df.address).alias("Details")).show()
Output:

PySpark – concat_ws()
Concat_ws() will join two or more columns in the given PySpark DataFrame and add these values into a new column. It will separate each column’s values with a separator.
By using the select() method, we can view the column concatenated, and by using an alias() method, we can name the concatenated column.
Syntax
where,
- dataframe is the input PySpark Dataframe
- concat() – It will take multiple columns to be concatenated – column will be represented by using dataframe.column
- new_column is the column name for the concatenated column.
- the separator can be anything like space, special character, etc.
Example 1
In this example, we will concatenate height and weight columns into a new column and name the column as Body Index separated with “ _.” Finally, we will only select this column and display the DataFrame using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import concat_ws function
from pyspark.sql.functions import concat_ws
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# concatenating height and weight into a new column named - "Body Index"
df.select(concat_ws("_",df.height,df.weight).alias("Body Index")).show()
Output:

Example 2
In this example, we will concatenate rollno, name, and address columns into a new column and name the column as Details separated by “ ***.” Finally, we will only select this column and display the DataFrame using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import concat_ws function
from pyspark.sql.functions import concat_ws
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# concatenating rollno , name and address into a new column named - "Details"
df.select(concat_ws("***",df.rollno,df.name,df.address).alias("Details")).show()
Output:

Conclusion
We can concatenate two or more columns by using concat() and concat_ws() methods. The main difference between the two methods is we can add a separator in the concat_ws() method.