Quick Outline
This post will show:
How to Use an Agent to Return a Structured Output in LangChain
- Installing Frameworks
- OpenAI Environment
- Creating a Vector Store
- Setting the Path
- Loading & Splitting the Data
- Creating a Retriever
Method 1: Combining Agent with Vector Stores
Method 2: Using Agent as a Router
Method 3: Using Agent With Multi-Hop Vector Store
How to Use an Agent to Return a Structured Output in LangChain?
The developer uses agents to route between the databases containing training data for the models. An agent has the blueprint of the complete process by storing all the steps. The agent has the tools to perform all these activities to complete the process. The user can also use the agent to get data from different data stores to make the model diverse.
To learn the process of combining agents and vector stores in LangChain, simply follow the listed steps:
Step 1: Installing Frameworks
First, install the LangChain module and its dependencies for combining the agents and vector stores:
In this guide, we are using the Chroma database which can store data in different locations or tables:
To get a better understanding of data, split the large files into smaller chunks using the tiktoken tokenizer:
OpenAI is the module that can be used to build the large language model in the LangChain framework:
Step 2: OpenAI Environment
The next step here is to set up the environment using the OpenAI’s API key which can be extracted from the OpenAI official account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
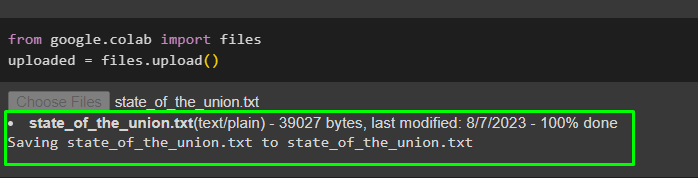
Now, upload the data from the local system to the Google collaboratory in order to use it in the future:
uploaded = files.upload()
Step 3: Creating a Vector Store
This step configures the first component of our task which is a vector store for storing the uploaded data. Configuring the vector stores requires the libraries that can be imported from different dependencies of the LangChain:
#Vector stores dependency to get the required database or vector
from langchain.vectorstores import Chroma
#Text splitter is used to convert the large text into smaller chunks
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.chains import RetrievalQA
llm = OpenAI(temperature=0)
Step 4: Setting the Path
After importing the libraries, simply set the path for accessing the vector stores before storing the data in it:
relevant_parts = []
for p in Path(".").absolute().parts:
relevant_parts.append(p)
if relevant_parts[-3:] == ["langchain", "docs", "modules"]:
break
#Conditional Statement inside the loop to set the path for each database
doc_path = str(Path(*relevant_parts) / "state_of_the_union.txt")
Step 5: Loading & Splitting the Data
Now, simply load the data and split it into smaller chunks to make its readability and understandability better. Create embeddings of the data by converting the text into numbers making their vector spaces and storing it in the Chorma database:
#Loading dataset from its path and store its smaller chunks in the database
loader = TextLoader(doc_path)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
#Convert text into numbers and store the embeddings in the database
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings, collection_name="state-of-union")
Step 6: Creating a Retriever
To combine agent and vector stores, it is required to create a retriever using the RetrievalQA() method from the LangChain framework. This retrieval method is recommended to get data from vector stores using the agents as the tool for working with the databases:
llm=llm, chain_type="stuff", retriever=docsearch.as_retriever()
)
Load another dataset to integrate the agent with multiple datasets or vector stores:
Store the ruff dataset in the chromadb after creating the smaller chunks of the data with the embedding vectors as well:
ruff_texts = text_splitter.split_documents(docs)
ruff_db = Chroma.from_documents(ruff_texts, embeddings, collection_name="ruff")
ruff = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=ruff_db.as_retriever()
)
Method 1: Combining Agent with Vector Stores
The first method of combining both agents and vector stores to extract information is mentioned below:
Step 1: Configure Tools
Now that the vector stores are configured, moving on towards building the second component of our process i.e. agent. To create the agent for the process, import the libraries using the dependencies like agents, tools, etc.
from langchain.agents import AgentType
#Getting Tools from the LangChain to build the agent
from langchain.tools import BaseTool
from langchain.llms import OpenAI
#Getting LLMMathChain from chains to build the language model
from langchain.chains import LLMMathChain
from langchain.utilities import SerpAPIWrapper
from langchain.agents import Tool
Configure the tools to be used with the agents using the QA system or retrieval configured earlier with the name and description of the tools:
Tool(
name="State of Union QA System",
func=state_of_union.run,
description="Provides responses to the questions related to the loaded dataset with input as a fully formed question",
),
Tool(
name="Ruff QA System",
func=ruff.run,
description="Provides responses to the questions about ruff (a python linter) with input as a fully formed question",
),
]
Step 2: Initialize Agent
Once the tools are configured, simply set the agent in the argument of the initializa_agent() method. The agent we are using here is the ZERO_SHOT_REACT_DESCRIPTION along with the tools, llm (language model), and verbose:
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Step 3: Test the Agent
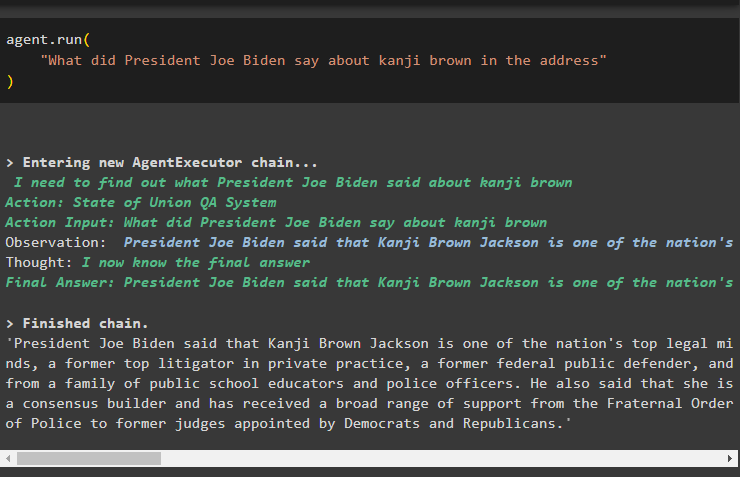
Simply execute the agent using the run() method that contains the question in its argument:
"What did President Joe Biden say about kanji brown in the address"
)
The following screenshot displays the answer extracted from both the data stores using the observation stored in the memory of the agent:
Method 2: Using Agent as a Router
Another way to combine both components is by using the agent as a router and the following explains the process:
Step 1: Configure Tools
Using the agent as the router means that the RetrievalQA system will return the output directly as the tools are configured to return the output directly:
#configuring the tools required to build the agent for getting data from the data
Tool(
name="State of Union QA System",
func=state_of_union.run,
description="Provides responses to the questions related to the loaded dataset with input as a complete question",
return_direct=True,
),
Tool(
name="Ruff QA System",
func=ruff.run,
description="Provides responses to the questions about ruff (a python linter) with input as a complete question",
return_direct=True,
),
]
Step 2: Initialize and Test the Agent
After setting the tools simply set the agent which can be used solely as the router using the initialize_agent() method:
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
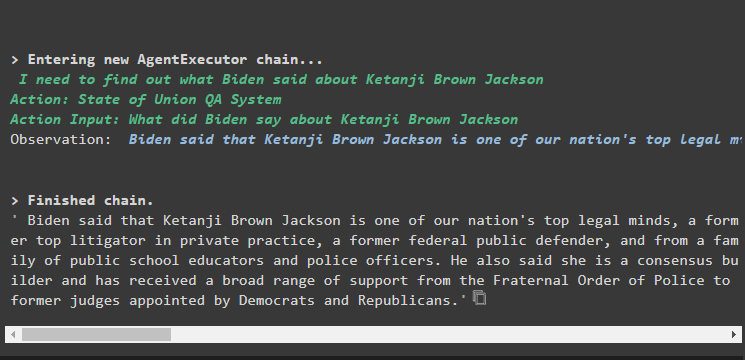
Test the agent by giving the input question in the agent.run() method by executing the following command:
"What did President Joe Biden say about kanji brown in the address"
)
Output
The output screenshot displays that the agent has simply returned the answer to the question from the dataset extracted by the RetrievalQA system:
Method 3: Using Agent With Multi-Hop Vector Store
The third method in which the developers can combine both agent and vector stores is for the multi-hop vector store queries. The following section explains the complete process:
Step 1: Configure Tools
The first step is, as usual, the configuration of tools used for building the agents to extract data from the data stores:
Tool(
name="State of Union QA System",
func=state_of_union.run,
description="Provides responses to the questions related to the loaded dataset with input as a fully formed question, not referencing any pronouns from the previous conversation",
),
Tool(
name="Ruff QA System",
func=ruff.run,
description="Provides responses to the questions related to the loaded dataset with input as a fully formed question, not referencing any pronouns from the previous conversation",
),
]
Step 2: Initialize and Test the Agent
After that, build the agent variable using the initialize_agent() method with the name of the agent:
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
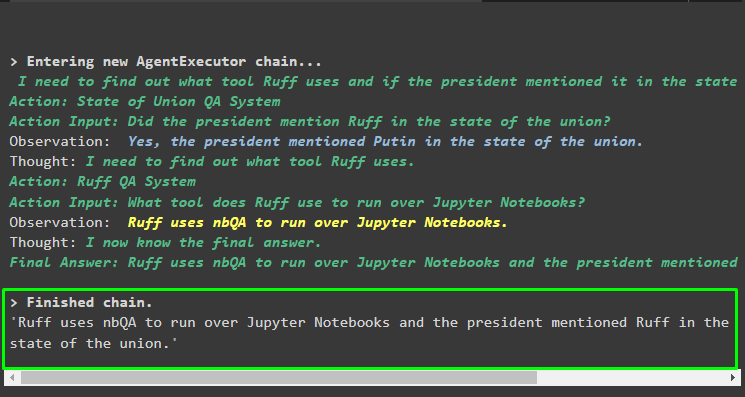
Run the agent using the multi-hop question that contains more than one aspect or feature as the following code block contains such a question:
"What tool does ruff use to run over Python notebooks and Did any of the speaker mention the tool in their address"
)
Output
The following screenshot suggests that the agent has to work through the question to understand its complexity. It has returned the answer extracted by the QA system from the multiple data stores we uploaded earlier in the process:
That’s all about how to combine agents and vector stores in LangChain.
Conclusion
To combine agents with the vector stores in LangChain, start with the installation of modules to set up the environment and load datasets. Configure the vector stores to load data by splitting it into smaller chunks first and then build the language model using the OpenAI() method. Configure the agent to integrate it with the vector store to extract data for different kinds of queries. This article has elaborated on the process of combining agents and vector stores in LangChain.