The algorithms for character sorting are quite lengthy and cumbersome to explain. Therefore, in this Linux Hint article, we will give a brief overview of the character encoding and sorting the mean based on various local data. We will then explain how to use the two basic features that C provides to handle the character strings based on the language and collation of the various local data used in computing.
It is very important to clarify that Unicode encoding is a multi-byte encoding, so one character can occupy multiple “chars”. Although, in this article, we will see the two basic functions to handle the characters with collation in the data of type “char”. The “wchar.h” header defines the multibyte characters and provides similar functions for handling the characters with large size.
Character Encoding
Character encoding is the assignment of a representative binary numeric value to each alphabetic character, symbol, special character, or control character
The ASCII code is one of the simplest and most widely used “i” C language. It is the encoding that we usually use for characters of “char” type that we put into strings. This encoding uses a single byte per character, 7 bits to represent each character of most western alphabets, as well as their control and special characters. The remaining bit is used for parity checking during error detection. In the extended version, all 8 bits are used to represent the additional characters.
While ASCII met the requirements of most Western Latin alphabets, it did not for Eastern alphabets. The Unicode encoding includes all characters of the alphabets of all Western and Eastern languages. This is why it is currently one of the most widely used, thanks to its portability in text encoding, its flexibility, and compatibility with the ASCII code.
This extensive set of encoded characters is divided into groups, each of which has a specific lexicographic order to form the alphabet for each language or region.
Collation of Characters
The portability and exchange of information often means that we have to process the characters and files written in another region. The lexicographic order of the characters that is used in the alphabet that created them does not match the one that is used by our system.
An example of this is the difference between the Latin alphabet which has 26 letters and the Spanish alphabet which has 27 letters. In the Latin alphabet, the letter that follows the “N” is the “O”. But in the Spanish alphabet, it is followed by ” Ñ”. Next, we see a table with these letters and their decimal number of representation in ASCII:
| English | Spanish | ||
| N | 110 | N | 110 |
| O | 111 | Ñ | 165 |
These differences make it necessary to rearrange the characters according to the alphabet and the zone in which the text is to be interpreted.
Local Data of the Operating System
Every time we turn on our computer, Linux loads a set of predefined parameters set during installation or later modified by the user that determines the language, encoding, type of characters used, and sorting rules for the region. This determines how the text is rendered and displayed by the system
These parameters are called local data. We can display them in the Linux console using the following command:
This command displays in the console. Among other things, the parameters for the system’s local data, language, character encoding, and sorting for that region.
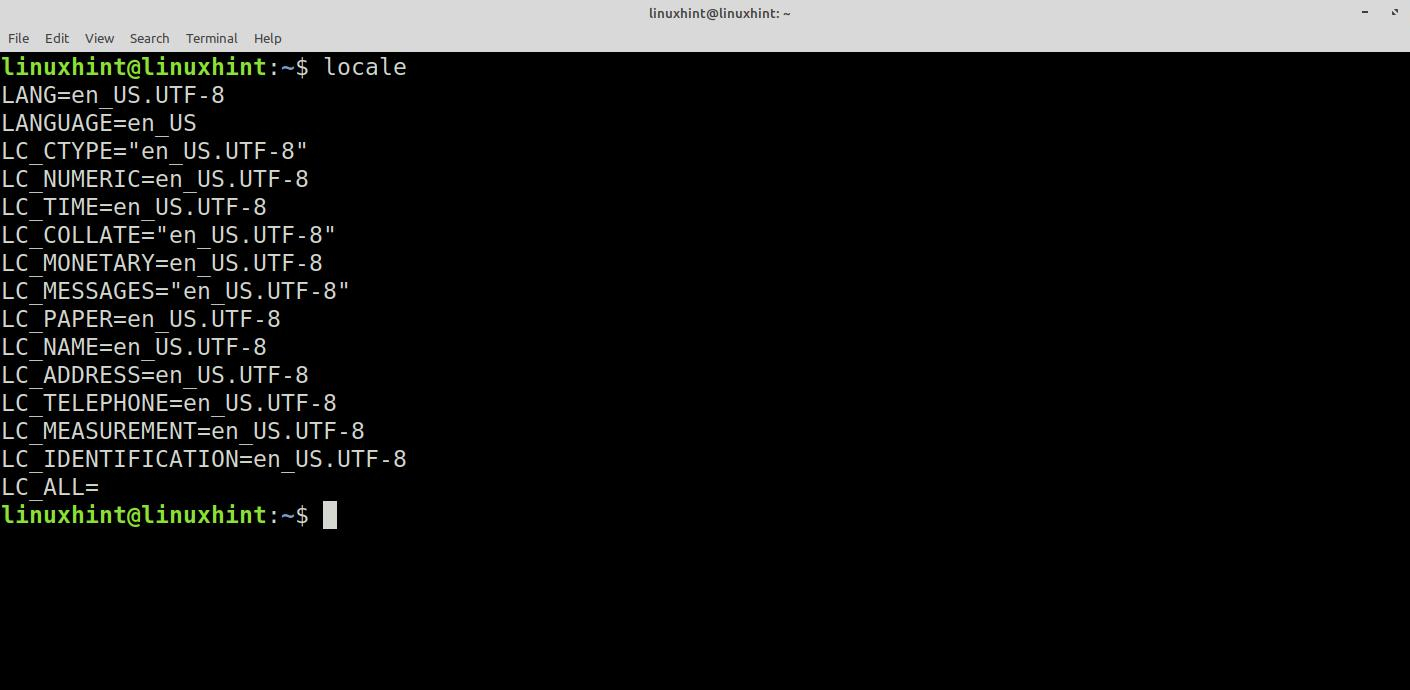
As we can see in the figure, the encoding for the regional English language of the United States is en_US.UTF-8. To see the list of different local data and encodings installed in our OS, we need to run the following command:
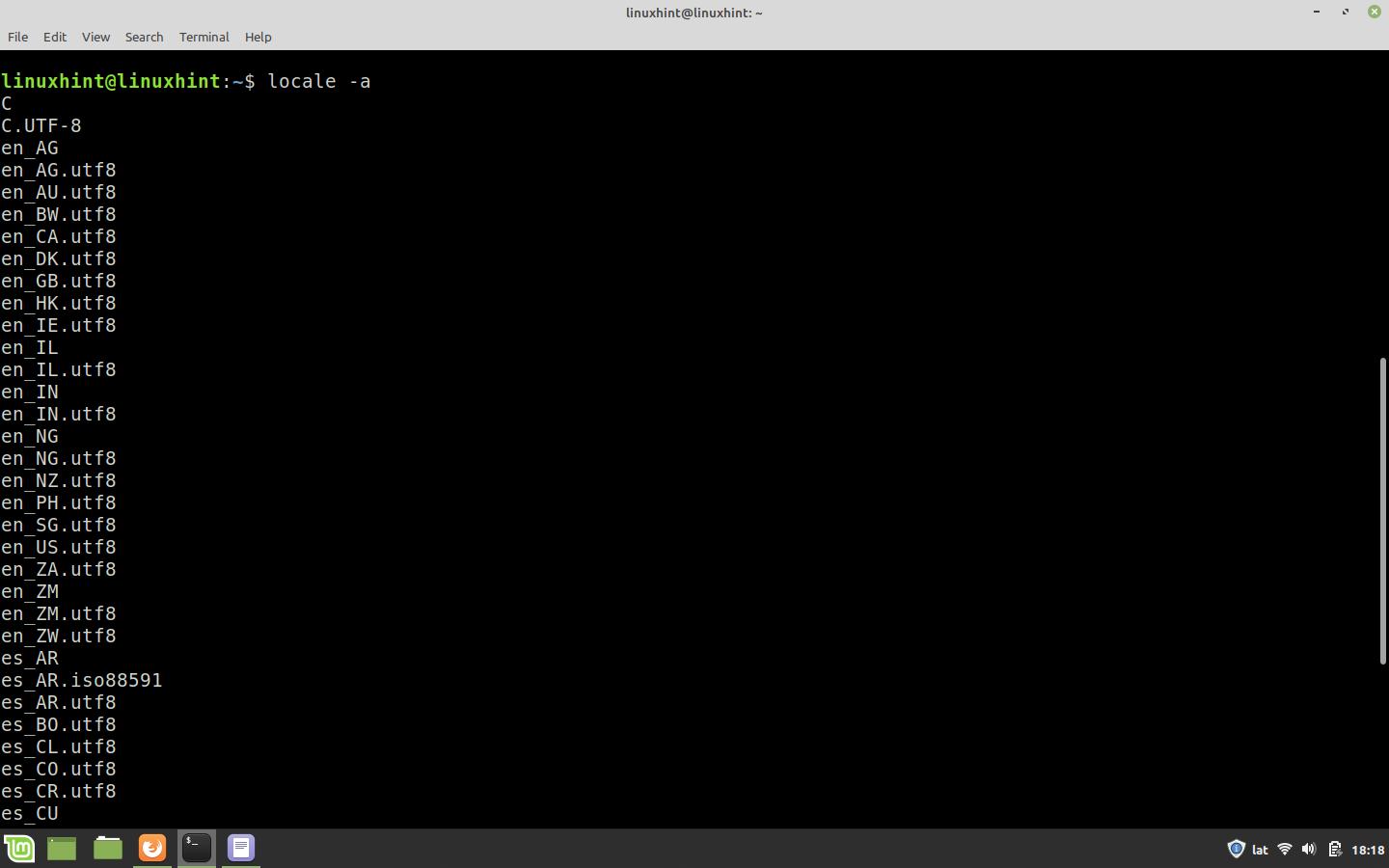
The following figure shows the list of locale data which is installed in the operating system.
Note that while the language is the same for all options, in this case is the English (en), the encoding and sorting settings are not. The one for the United States is “en_US” while the one for Canada is “in_ CA”.
How to Select the Local Data of a Program with the Setlocale() Function in the C Language
The same parameters that are returned by the command “~$ locale” in the Linux console are defined in the “locale.h” header in C with identical syntax and representation and can be changed in the local instance with the setlocale function.
Syntax of the Setlocale() Function in the C Language
Description of the Setlocale() Function in the C Language
The setlocale() function selects the local data that the program that we are compiling uses. We can also check the current configuration. If these parameters are not set by this function in the code, the program defaults to using the local data of the system on which it runs.
Next, let us look at the list of the most important parameters that the setlocale() changes or queries that affect the language and sorting process:
LANGUAGE= Modifies or consults the local language.
LC_CTYPE= Specifies or queries the type of characters for the locale.
LC_NUMERIC= Specifies or queries the type of numeric characters.
LC_TIME= Specifies or queries the calendar and time data for the local setting.
LC_COLLATE= Specify or query the character collation rules.
LC_ALL= Specifies or queries the entire local data set.
The strxfrm() function is defined in the “string.h” header. To use it, we need to include it in our code as follows:
How to Query the Current Locale Configuration of the System with the Setlocale() Function in C
The setlocale function provides the ability to change the locale data in general or each of its parameters individually. It also provides the possibility to query the used configuration.
To do this, we must call the setlocale() function and pass the parameter that we want to query as the first input argument and an empty string as the second argument.
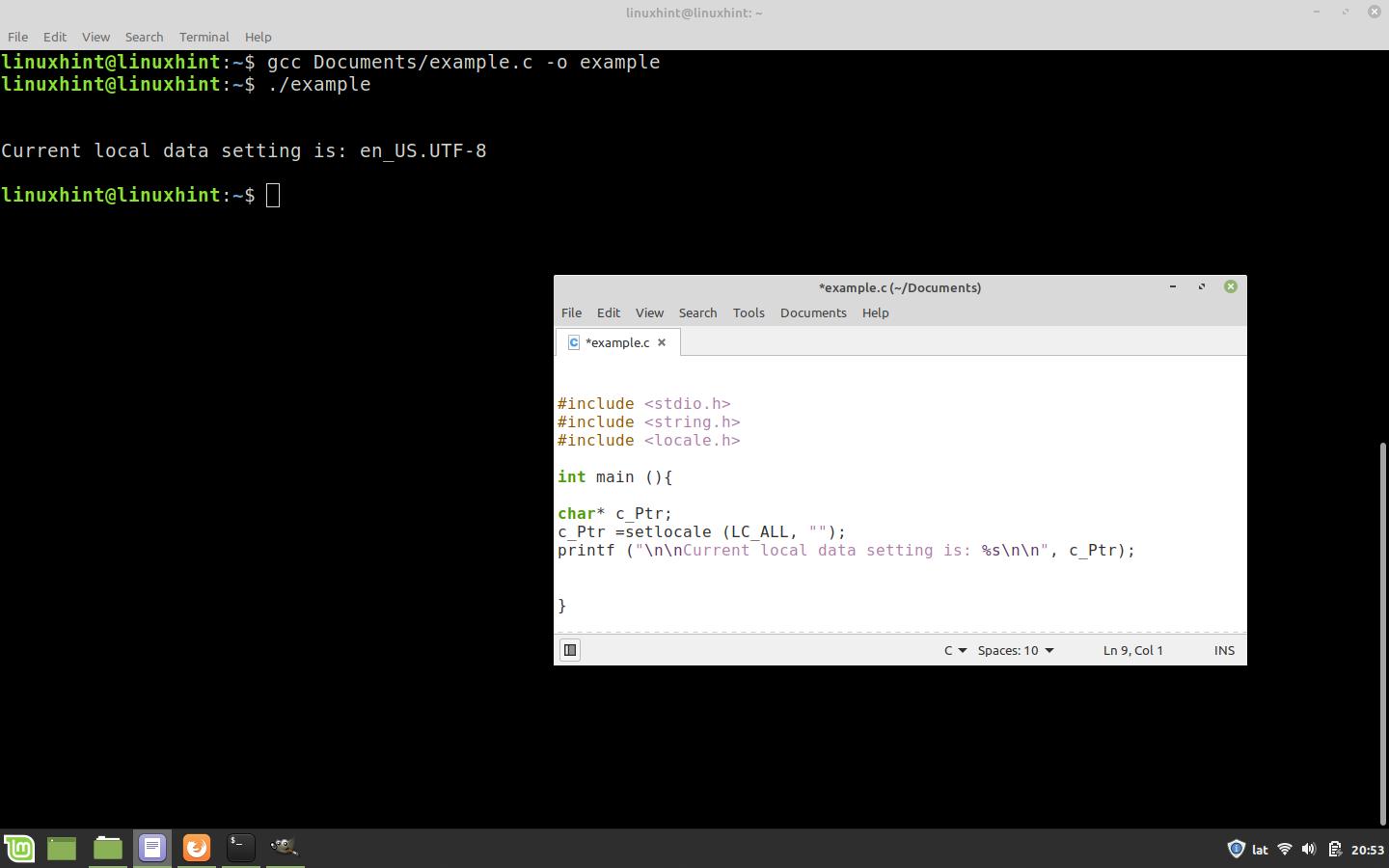
The setlocale() function returns the pointer to a string which contains the name of the current locale data. The following is the code that queries the current configuration and displays it in the command console:
As seen in the following image, setlocale returns a string with the current locale:
How to Select the Current Local and Collation Configuration with the Setlocale() Function in C
The setlocale() function can be used to select or change the local data in general with “LC _ALL” or via the individual parameters to perform the collation of characters based on the range we choose.
To do this, we need to call the setlocale() function and pass the parameter that we want to change as the first argument and a string with the local configuration that we want to select as the second argument.
Here is the code to select the UTF-8 encoded Canada locale collation:
#include <string.h>
#include <locale.h>
void main (){
setlocale (LC_ALL, "en_CA.UTF-8");
}
As we have seen so far, the sorting is completely tied to the selected locale. Next, let us look at the two functions that the C language provides to handle the strings based on our chosen local configuration: strxfrm() and strcoll().
Strxfrm() Function in C Language
Syntax:
Description of the Strxfrm() Function in the C Language
The strxfrm() function copies the “s2” string with “n” characters and stores it to convert it to “s1” in the collation of the locale that is selected with setlocale(). If the locale setting is not previously selected with setlocale(), the collation is based on the current system setting.
The strxfrm() function returns an integer with the number of characters that the new string takes since the number of characters in the collation may be more or less than that of the original string.
The strxfrm() function works similarly to the strcpy() function, except that it allows us to specify which zone configuration rules that the new string should return. This adds flexibility to the use of this function since we can use setlocale() and strxfrm() to convert the strings with the locale that we choose, as well as create them.
The strxfrm() function is defined in the “string.h” header. To use it, we need to include it in our code as follows:
How to Convert a String with a Locale and a Specific Sort Order Using the Strxfrm() Function in C
In this example, we create the “str_2” string with local data from the United States and convert it to the “str_1″ string with local data configured for Spain.
To do this, we use the setlocale() to set the sort order for the locale of Spain LC _COLLATE = ” es_ ES”. We convert “str_2” to the “str_1” string with strxfrm(). You can find the code for this purpose in the following illustration:
Strcoll() Function in C Language
Syntax:
Description of the Strcoll() Function in the C Language
The strcoll() function compares the “s2” with “s1” string based on the collation of the locale selected with setlocale(). If the locale setting is not previously selected with setlocale(), the collation is based on the current system setting.
The strcoll() function returns an integer equal to 0 if the strings are equal. The result is greater than 0 if s2 is greater than s1. The result is less than 0 if it is less than s1.
This function works similarly to strcmp() with the difference that we can use it to specify which zone configuration rules does the strings should be compared to.
The strcoll() function is defined in the “string.h” header. To use it, we have to include it in our code as follows:
Compare Two Strings Using the Specific Sort Configuration with the Strcoll() Function in C
In this example, we compare the “str_2” string with “str_1” string using a specific sort configuration. In this case is Spanish from Argentina, namely “es_ AR”.
For this purpose, we create two strings that contain the same text except that “str_2” has an accent on the fifth letter. The accent is a symbol over a letter used in Spanish, so the glyph for this character is different. Then, we set the locale for Argentina and compare the strings with the strcoll() function. We store the result in the “cn” integer and output it to the command console with printf().
The following is the code for this comparison:
Conclusion
In this Linux Hint article, we briefly explained what character encoding means in Computer Science so that you have a clearer idea of what character encoding means depending on the local configurations used by computer systems. Then, we showed you how to use the two basic features that the C language provides to handle the character collation strings. We hope that this article is useful to you. For more articles about the C language and Linux tips, use the site’s search engine.