[adthrive-in-post-video-player video-id=”EZjrgDqo” upload-date=”2020-05-08T20:02:37.000Z” name=”How to Clear Cache on Linux” description=”How to Clear Cache on Linux” player-type=”collapse” override-embed=”true”]
How Linux File System Cache Works
The kernel reserves a certain amount of system memory for caching the file system disk accesses in order to make overall performance faster. The cache in linux is called the Page Cache. The size of the page cache is configurable with generous defaults enabled to cache large amounts of disk blocks. The max size of the cache and the policies of when to evict data from the cache are adjustable with kernel parameters. The linux cache approach is called a write-back cache. This means if data is written to disk it is written to memory into the cache and marked as dirty in the cache until it is synchronized to disk. The kernel maintains internal data structures to optimize which data to evict from cache when more space is needed in the cache.
During Linux read system calls, the kernel will check if the data requested is stored in blocks of data in the cache, that would be a successful cache hit and the data will be returned from the cache without doing any IO to the disk system. For a cache miss the data will be fetched from IO system and the cache updated based on the caching policies as this same data is likely to be requested again.
When certain thresholds of memory usage are reached background tasks will start writing dirty data to disk to ensure it is clearing the memory cache. These can have an impact on performance of memory and CPU intensive applications and require tuning by administrators and or developers.
Using Free command to view Cache Usage
We can use the free command from the command line in order to analyze the system memory and the amount of memory allocated to caching. See command below:
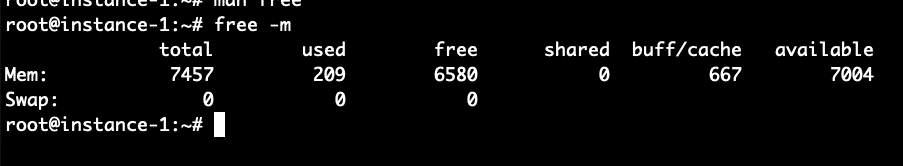
What we see from the free command above is that there is 7.5 GB of RAM on this system. Of this only 209 MB is used and 6.5 MB is free. 667 MB is used in the buffer cache. Now let’s try to increase that number by running a command to generate a file of 1 Gigabyte and reading the file. The command below will generate approximately 100MB of random data and then append 10 copies of the file together into one large_file.
# for i in `seq 1 10`; do echo $i; cat data_file >> large_file; done
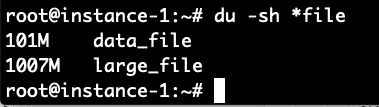
Now we will make sure to read this 1 Gig file and then check the free command again:
# free -m

We can see the buffer cache usage has gone up from 667 to 1735 Megabytes a roughly 1 Gigabyte increase in the usage of the buffer cache.
Proc Sys VM Drop Caches Command
The linux kernel provides an interface to drop the cache let’s try out these commands and see the impact on the free setting.
# free -m

We can see above that the majority of the buffer cache allocation was freed with this command.
Experimental Verification that Drop Caches Works
Can we do a performance validation of using the cache to read the file? Let’s read the file and write it back to /dev/null in order to test how long it takes to read the file from disk. We will time it with the time command. We do this command immediately after clearing the cache with the commands above.

It took 8.4 seconds to read the file. Let’s read it again now that the file should be in the filesystem cache and see how long it takes now.
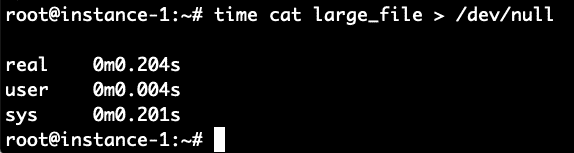
Boom! It took only .2 seconds compared to 8.4 seconds to read it when the file was not cached. To verify let’s repeat this again by first clearing the cache and then reading the file 2 times.
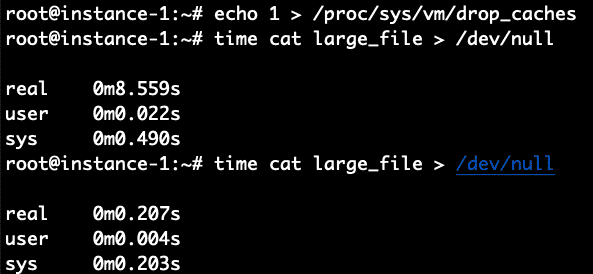
It worked perfectly as expected. 8.5 seconds for the non-cached read and .2 seconds for the cached read.
Conclusion
The page cache is automatically enabled on Linux systems and will transparently make IO faster by storing recently used data in the cache. If you want to manually clear the cache that can be done easily by sending an echo command to the /proc filesystem indicating to the kernel to drop the cache and free the memory used for the cache. The instructions for running the command were shown above in this article and the experimental validation of the cache behavior before and after flushing were also shown.