Example:
Here we are going to create PySpark dataframe with 5 rows and 6 columns.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:

Method 1: Using withColumnRenamed()
We can change the column name in the PySpark DataFrame using this method.
Syntax:
dataframe.withColumnRenamed(“old_column “,”new_column”)
Parameters:
- old_column is the existing column
- new_column is the new column that replaces the old_column
Example:
In this example, we are replacing the address column with “City” and displaying the entire DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rename the address column with City
df.withColumnRenamed("address","City").show()
Output:

We can also replace multiple column names at a time using this method.
Syntax:
dataframe.withColumnRenamed(“old_column “,”new_column”) .withColumnRenamed(“old_column “,”new_column”)………… .withColumnRenamed(“old_column “,”new_column”)
Example:
In this example, we are replacing the address column with “City”, height column with “HEIGHT”, rollno column with “ID”, and displaying the entire DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
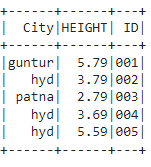
#rename the address column with City, height column with HEIGHT , rollno column with ID
df.withColumnRenamed("address","City").withColumnRenamed("height","HEIGHT").withColumnRenamed("rollno","ID").show()
Output:

Method 2: Using selectExpr()
This is an expression method which changes the column name by taking an expression.
Syntax:
dataframe.selectExpr(expression)
Parameters:
- It will take only one parameter which is an expression.
- Expression is used to change the column. So, the expression will be: “old_column as new_column”.
Finally the syntax is:
dataframe.selectExpr(“old_column as new_column”)
where,
- old_column is the existing column
- new_column is the new column that replaces the old_column
Note : We can provide multiple expressions separated by comma within this method.
Example 1:
In this example, we are replacing the address column with “City” and displaying this column using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rename the address column with City
df.selectExpr("address as City").show()
Output:

Example 2:
In this example, we are replacing the address column with “City”, height column with “HEIGHT”, rollno column with “ID”, and displaying the entire DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rename the address column with City, height column with HEIGHT , rollno column with ID
df.selectExpr("address as City","height as HEIGHT","rollno as ID").show()
Output:

Method 3: Using select()
We can select columns from the DataFrame by changing the column names through col with alias() method.
Syntax:
dataframe.select(col(“old_column”).alias(“new_column”))
Parameters:
- It will take only one parameter which is column name through col() method.
col() is a method which is available in pyspark.sql.functions will take old_column as input parameter and change to new_column with alias()
alias() will take new_column as a parameter
where:
- old_column is the existing column
- new_column is the new column that replaces the old_column
Note : We can provide multiple columns separated by comma within this method.
Example 1:
In this example, we are replacing the address column with “City” and displaying this column using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rename the address column with City
df.select(col("address").alias("City")).show()
Output:

Example 2:
In this example, we are replacing the address column with “City”, height column with “HEIGHT”, rollno column with “ID” and displaying the entire DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rename the address column with City, height column with HEIGHT , rollno column with ID
df.select(col("address").alias("City"),col("height").alias("HEIGHT"),col("rollno").alias("ID")).show()
Output:
Conclusion
In this tutorial, we discussed how to change the column names of PySpark DataFrame using withColumnRenamed(), select, and selectExpr() methods. Using these methods, we can also change multiple column names at a time.