Backups are incredible features, especially when working with data-critical environments. In Apache Cassandra, we can create backups of database data stored as SSTable files. You can then use the backup files to restore the database in the case of data loss, node, or partition failure. Backups can also be used to replicate the database in another machine, removing the need to recreate the structure from scratch.
Cassandra supports two main types of backups:
- Snapshots
- Incremental Backups
In this tutorial, we will focus on snapshot backups. First, we learn how we can initialize and create the database backups stored in an Apache Cassandra cluster.
Let’s dive in.
What Are Snapshots?
In the context of an Apache Cassandra cluster, a snapshot refers to a copy of a table’s SSTable files at a specific time. SSTable or Sorted Strings Table is a file format that Apache Cassandra uses to store the in-memory data in memtables for fast access. SSTable files are immutable and are removed or merged with new SSTable files as the data changes.
Snapshots in Cassandra can be issued manually by the user or automated by enabling the feature in the configuration files.
Setting Up a Sample Data to Illustrate the Snapshots in Cassandra
Before illustrating how to perform the snapshots in Cassandra, let us create some sample data to demonstrate how to create snapshots.
Let’s start by creating a snapshot.
... WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1};
The previous query creates a keyspace with the SimpleStrategy and replication factor of 1.
We can then switch to that keyspace and create two tables:
Next, create a users’ table as follows:
... id int,
... username text,
... email text,
... PRIMARY KEY(id)
... );
We can also create another table that is called with a similar structure:
... id int,
... username text,
... email text,
... PRIMARY KEY(id)
... );
Finally, we can add some sample data to the table as shown:
INSERT INTO users (id, username, email) VALUES (1, 'username2', '[email protected]');
INSERT INTO users_copy (id, username, email) VALUES (0, 'username1', '[email protected]');
INSERT INTO users_copy (id, username, email) VALUES (1, 'username2', '[email protected]');
We can then query the tables as follows:
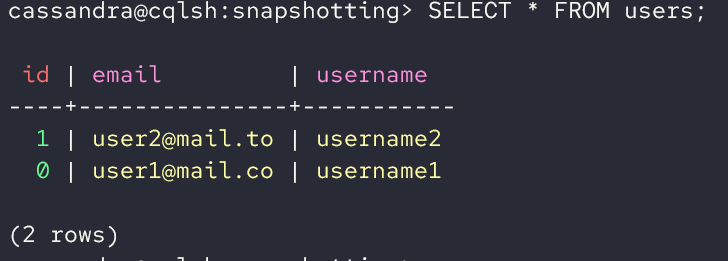
Output:

Configure the Cassandra Cluster for Snapshots
Before creating any snapshots, it’s good to ensure that automatic snapshot creation is disabled. Edit the cassandra.yml file and set the following value:
It’s also recommended to disable the automatic compaction before the snapshot creation. In the cassandra.yml file, set the following value:
Once the given settings are ready, restart your Cassandra cluster to apply the changes.
Taking Snapshots of All Keyspaces
When manually creating snapshots in Cassandra, we use the nodetool command. You can run the following command:
To view the available command options.
To take a snapshot of all the keyspaces in the Cassandra cluster, we can run the following command:
The command should return a message as shown:

By default, Cassandra creates a snapshot with the name of the current timestamp.
To specify the name of the snapshot, you can use the -t option as shown in the following command:
This creates a snapshot of all the keyspaces in the cluster and store it in the backups directory.

Taking a Snapshot of a Single Keyspace
You can also take a backup of a single keyspace in the cluster by specifying the keyspace name. For example, to take a snapshot of the snapshotting keyspace that we created earlier, we can run the following command:
Cassandra creates a snapshot directory for each table in the specified keyspace. For example, since the “snapshotting” keyspace contains two tables, Cassandra creates a snapshot directory for each.
By default, Cassandra stores the snapshots in the /var/lib/cassandra/data directory.
You should see directories of each table in the keyspace.

Inside each file, you will find the other files and directories as shown:
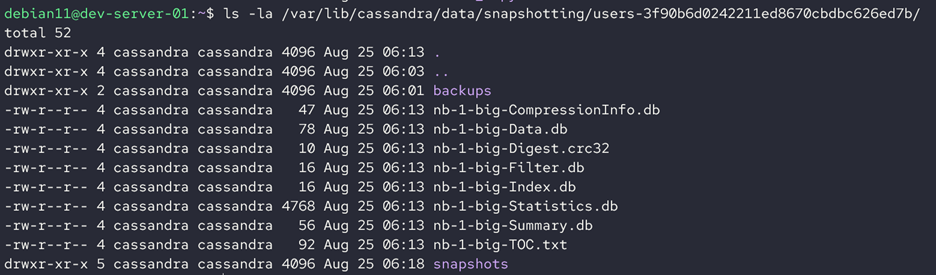
Taking a Snapshot of a Single Table Within a Keyspace
Sometimes, you may want to take a snapshot of a specific table within a given keyspace. For that, you can use the –table option followed by the name of the table that you wish to backup.
For example, to take a snapshot of the users_copy table in the “snapshotting” keyspace, we can run the following command:
The command creates a snapshot of the users_copy table and store it under the uc_snap directory.

Listing Snapshots
To view the available snapshots in the cluster, use the listsnapshot command as shown:
You should get a list of all the available snapshots and details such as the snapshot name, to which keyspace they belong, the column family name, the size on disk, and the actual size.
Snapshot name Keyspace name Column family name True size Size on disk
uc_snap snapshotting users_copy 0 bytes 5.87 KiB
1661397218984 system_schema columns 0 bytes 12.51 KiB
1661397218984 system_schema types 0 bytes 15.03 KiB
1661397218984 system_schema indexes 0 bytes 15.15 KiB
1661397218984 system_schema keyspaces 0 bytes 5.81 KiB
1661397218984 system_schema dropped_columns 0 bytes 15.63 KiB
1661397218984 system_schema aggregates 0 bytes 15.4 KiB
1661397218984 system_schema triggers 0 bytes 15.15 KiB
1661397218984 system_schema tables 0 bytes 10.27 KiB
1661397218984 snapshotting users 0 bytes 5.86 KiB
1661397218984 snapshotting users_copy 0 bytes 5.87 KiB
snapshotting_backup snapshotting users 0 bytes 5.86 KiB
snapshotting_backup snapshotting users_copy 0 bytes 5.87 KiB
backups snapshotting users 0 bytes 5.86 KiB
backups snapshotting users_copy 0 bytes 5.87 KiB
1661397899477 snapshotting users_copy 0 bytes 5.87 KiB
Total TrueDiskSpaceUsed: 0 bytes
Conclusion
In this article, you learned how snapshotting works in Apache Cassandra. You also learned how to take snapshots of keyspaces, specific tables within a keyspace, and more.
Thanks for reading!