Apache Cassandra is built to ensure high availability in all environments. This means that if a single or multiple nodes with a cluster are unavailable, the other nodes within the cluster will handle the requested operations.
However, when the unavailable nodes become reachable, they need to know what operations they missed within the cluster. Therefore, Apache Cassandra uses a hint feature to alert the node(s) of all the functions that they missed while unavailable. Although hints can perform notification of the missing operations, it does not guarantee a complete data consistency across the cluster. This inconsistency can lead to data loss, especially if an active cluster multiplies the CRUD operations.
To prevent a data loss, you need to perform the data repairs, allowing the nodes to synchronize the data across the cluster with the updated information.
In this tutorial, you will discover how to perform the repairs manually in the Cassandra cluster using the nodetool utility.
Types of Repairs in Cassandra
Cassandra supports two main types of repairs:
- Incremental Repairs
- Full Repairs
Incremental Repairs
By default, Cassandra performs an incremental repair. This repair only repairs the data that has changed since the previous repair. This is less resource intensive and very useful when you regularly perform the repairs.
One disadvantage of incremental repairs is that once the data is marked as repaired, Cassandra will not attempt to repair it again. This can lead to data loss, especially if the repair becomes corrupt.
Full Repairs
On the other hand, full repairs are much resource intensive, especially on disk and network I/O operations. However, they perform the data repairs across the cluster, synchronizing the correct, up-to-date information.
We could spend this entire article on the various types of Cassandra repairs and how Cassandra handles the repairs. However, let’s get into the main course of the article.
The Nodetool Repair Command
To perform a data repair on a Cassandra cluster, we use the nodetool repair command. The command syntax and options are as shown:
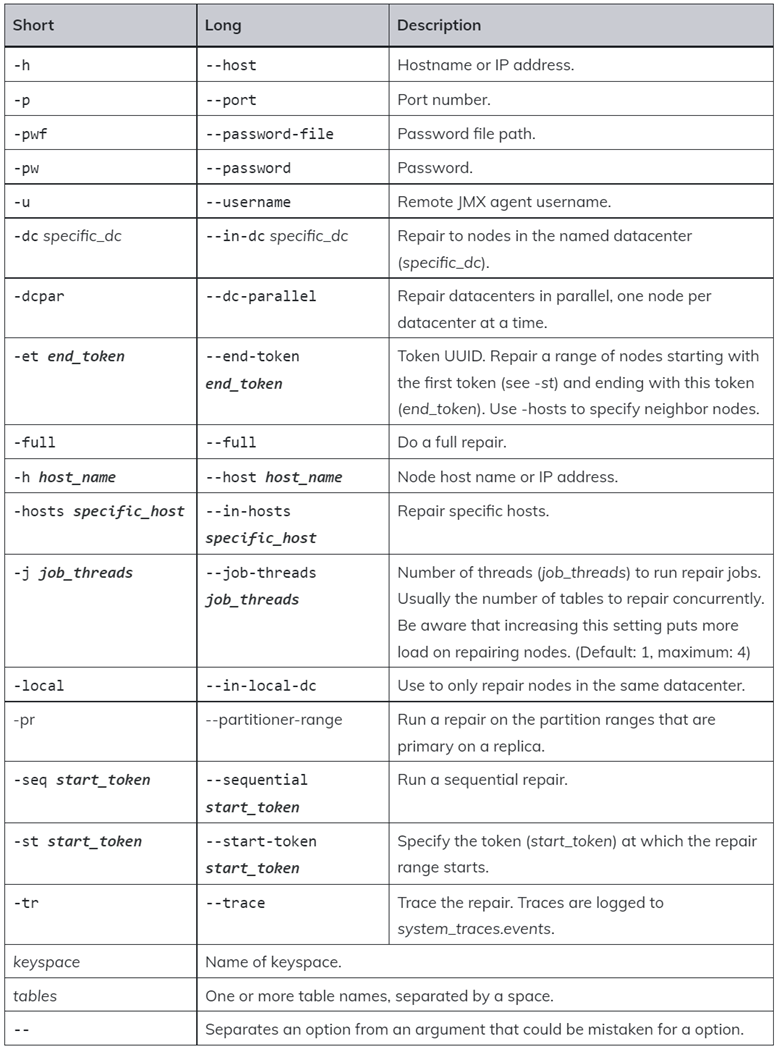
Depending on the specified method, the repair command performs either a full or incremental repair on one or more nodes.
How to Perform a Full Repair in Cassandra Cluster
In this section, let us look at how we can perform a full repair on a Cassandra cluster.
NOTE: To best illustrate a full repair, run the commands in this tutorial in a cluster with three or more nodes.
Step 1: Create a keyspace with a replication factor of 3 (or for the number of available nodes).
... WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 3};
Step 2: Create a table and add a sample data.
Step 3: Add a sample data.
cassandra@cqlsh:development> INSERT INTO t (id, name, age) VALUES (1, 'User2', 3);
cassandra@cqlsh:development> INSERT INTO t (id, name, age) VALUES (2, 'User3', 5);
Step 4: Get a data stored in the table.
Output:
----+-----+-------
1 | 3 | User2
0 | 2 | User1
2 | 5 | User3
Step 5: Update the keyspace to include 4 replicas.
... WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 4};
Increasing the number of replicas mimics the operation of a node in the cluster going down and coming back up.
Increasing the replication factor should give you a message to perform a data repair.
Step 6: Perform a full data repair as:
The previous command performs a full repair on all the tables in the specified keyspace. To repair only one table, we can run the following command:
This should repair only the table “t” in the keyspace.
To view the repair status, you can use the tpstats command:
Conclusion
In this article, you learned how to perform Cassandra’s full repair using the nodetool utility.
Thanks for reading!