Apache Cassandra is a free, open-source NoSQL database that is commonly used in large-scale and high-availability environments. Cassandra provides a query language that is closely similar to SQL in relational databases.
This query language allows you to perform the everyday operations from the command line using simple and intuitive commands.
Although Cassandra is not a traditional relational database, it borrows the standard features such as databases or keyspaces, tables, columns, and rows.
In Cassandra, a table refers to a set of key-value pairs that resemble a row and column in a relational database. Tables exist as nested entities of a specific Cassandra keyspace.
This guide will teach you how to create and drop a table within a specific Cassandra keyspace.
Cassandra – How to Create a Table
In Cassandra, we use the CREATE TABLE statement to create a table within a specific keyspace. The query syntax is as shown:
column_definition [, ...]
PRIMARY KEY (column_name [, column_name ...])
[WITH table_options
| CLUSTERING ORDER BY (clustering_column_name order])
| ID = 'table_hash_tag'
| COMPACT STORAGE]
By default, Cassandra creates a table under the currently selected keyspace. However, you can specify the keyspace where you wish to create the table using the dot notation.
The IF NOT EXISTS statement allows you to avoid errors if a table with the specified name already exists on the specified keyspace. Cassandra returns an error on name collision if you do not use the IF NOT EXISTS keyword.
This is because you cannot have more than one table with the same name in a given keyspace.
Next, inside the parenthesis, you provide your column definition. A single column definition includes properties such as the column name, data type of the column (must be a supported cql definition type), and other “constraints”.
Accepted constraints within a column definition include:
- STATIC – This states that the column should hold a single value.
- PRIMARY KEY = It sets the specified column as the primary key for that table.
When creating a table, ensure the following:
- There is only one primary key in that table.
- A static key is not set as the primary key.
Let’s start by creating a simple keyspace as shown:
This should create a simple keyspace with a replication factor of 1. Check our tutorial on creating Cassandra keyspaces to learn more.
We can then switch to that keyspace as follows:
Finally, we can create a simple table as:
... id UUID,
... full_name text,
... score int,
... PRIMARY KEY (id));
The previous statement should create a table called users in the Linuxhint keyspace.
We can then add a sample record as shown in the following:
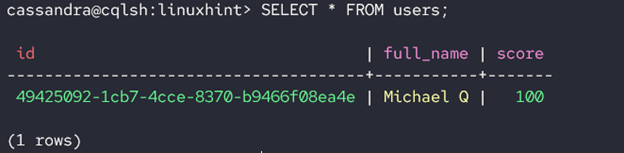
Show the table as:
Output:
Cassandra Drop Table
In Cassandra, we can drop a table using the DROP TABLE statement as shown in the following syntax:
Similarly, the drop command drops the table in the current keyspace unless specified. For example, to drop the users’ table in the Linuxhint keyspace, we can run the following command:
If we are in a different keyspace, we can explicitly specify the target keyspace as follows:
NOTE: Cassandra prevents you from dropping the tables with existing materialized views. Hence, before dropping a table, remove any corresponding materialized views.
Conclusion
In this article, we covered the process of creating and dropping a table from a specific keyspace in a Cassandra cluster.