This post demonstrates the process of working with a caching layer of LLMs using LangChain.
How to Work With Caching Layers of LLMs Using LangChain?
To work with the caching layer of LLMs using LangChain, simply go on to read the following steps of this easy guide:
Install Prerequisites
Before heading to the process, simply install LangChain to work with a caching layer of LLMs:
Install all the required packages like watermark, openai, gptcache, and tiktoken to start working with the caching layers:
After installing all the required modules, simply configure the OpenAI by providing its API key using the following code:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Method 1: Using In-Memory Caching
Once the OpenAI API key is installed, simply get the LLM from LangChain to apply caching layer:
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
Import all the required libraries using the following code to use In-Memory caching of LLMs in LangChain:
from langchain.callbacks import get_openai_callback
langchain.llm_cache = InMemoryCache()
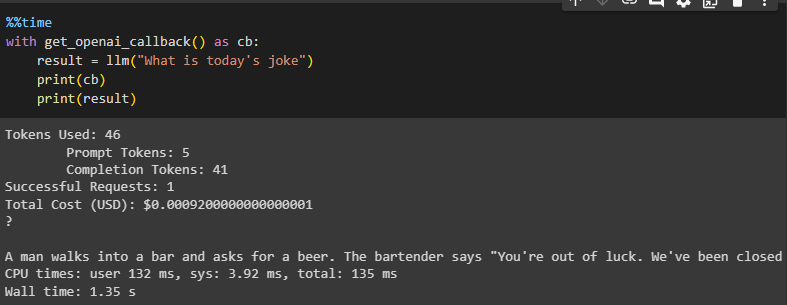
Use the callbacks() function to get the details of the query like how much time it took to get the answers and then also displays the answer fetched by the LLM:
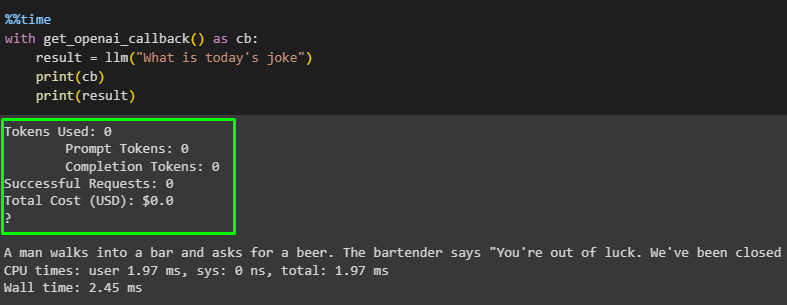
with get_openai_callback() as cb:
result = llm("What is today’s joke")
print(cb)
print(result)
After that, again use the same query to check whether the caching layer increase efficiency by reducing the time and cost of the query:
with get_openai_callback() as cb:
result = llm("What is today’s joke")
print(cb)
print(result)
The query has not used a single token and it was completed without any cost as it was stored in the In-Memory cache:
Method 2: Using SQLiteCache
The next caching method is using SQLiteCache, simply import the libraries and LLM for SQLiteCache by providing the path to the dataset:
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
Simply use the llm() function to post the query and get the answer from llm with the time it took to get the answer:
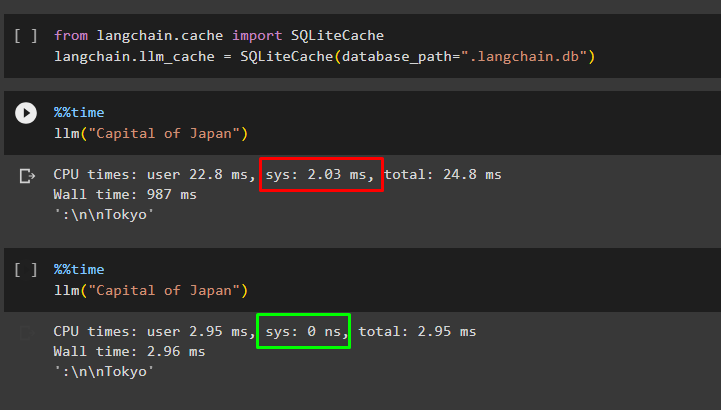
llm("Capital of Japan")
The query has consumed 2.03 ms of the system to get the answer from the database:
Again, use the following query and check its execution time as well:
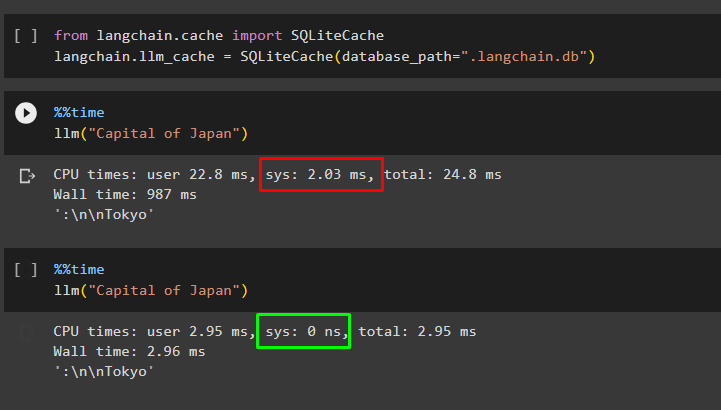
llm("Capital of Japan")
The query has not wasted any time of the system and the CPU usage has been reduced as well:
Method 3: Using GPT Caching
The LangChain framework also offers the use of GPT Cache which can be used with the following methods:
Let’s get started with the first method of using GPT Caching for LLMs:
3.1: Exact Match
The exact match caching method is the process of finding the exact answers from the cache memory using the libraries mentioned in the following code:
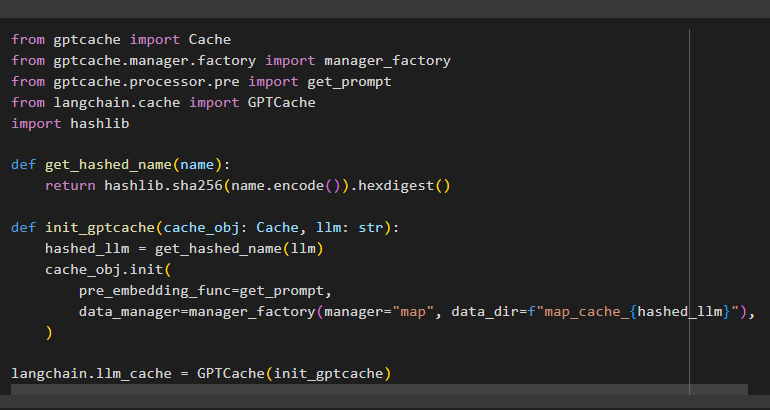
from gptcache.manager.factory import manager_factory
from gptcache.processor.pre import get_prompt
from langchain.cache import GPTCache
import hashlib
def get_hashed_name(name):
return hashlib.sha256(name.encode()).hexdigest()
def init_gptcache(cache_obj: Cache, llm: str):
hashed_llm = get_hashed_name(llm)
cache_obj.init(
pre_embedding_func=get_prompt,
data_manager=manager_factory(manager="map", data_dir=f"map_cache_{hashed_llm}"),
)
langchain.llm_cache = GPTCache(init_gptcache)
The above code uses two methods like get_hashed_name() and init_gptcache() to store hash names and call them to find exact matches respectively:
After that, simply ask a query using llm() function and get its time as well:
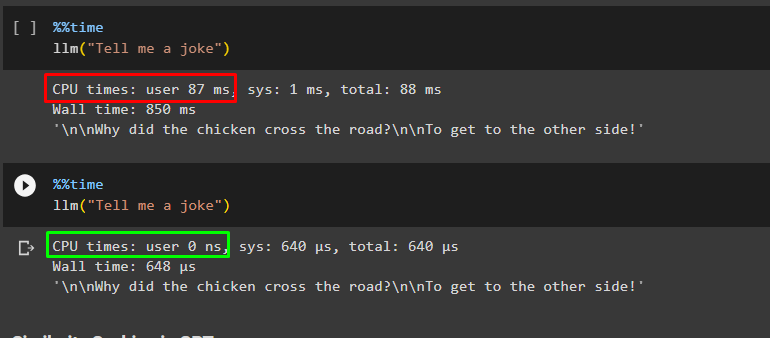
llm("Tell me a joke")
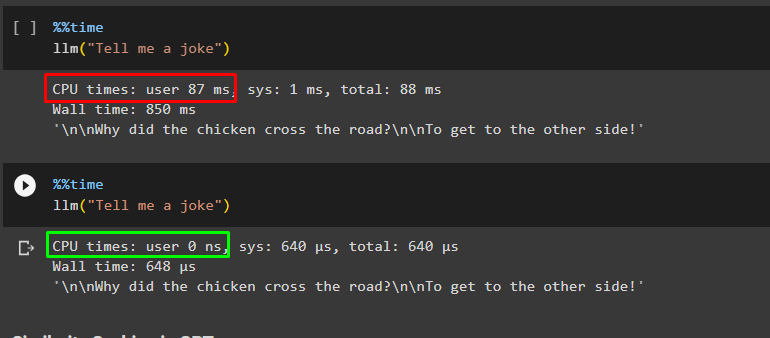
Again, use the same code with the same query to get the answer from the GPT cache:
llm("Tell me a joke")
The execution time has been reduced and the CPU hasn’t made any effort this time, so it is saving effort and time:
3.2: Semantic Similarity
The next method is using GPT Cache with semantic similarity. After that, its required libraries are imported using the following code. The code for configuring semantic similarity is like the above with just a name change from exact match to semantic similarity to manage the data:
from gptcache.adapter.api import init_similar_cache
from langchain.cache import GPTCache
import hashlib
#use the function to get the hash value as a name using semantic similarity
def get_hashed_name(name):
return hashlib.sha256(name.encode()).hexdigest()
#use the function to use the GPT cache function using semantic similarity
def init_gptcache(cache_obj: Cache, llm: str):
hashed_llm = get_hashed_name(llm)
init_similar_cache(cache_obj=cache_obj, data_dir=f"similar_cache_{hashed_llm}")
langchain.llm_cache = GPTCache(init_gptcache)
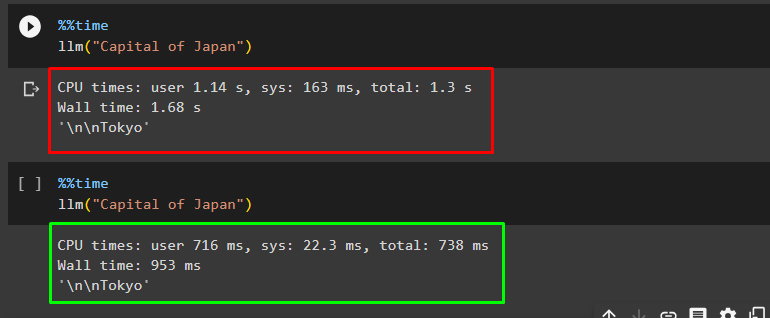
Get the execution time for the query by getting the answer according to the prompt:
llm("Capital of Japan")
The execution time for the above query is 1.68 seconds and the answer for the query is Tokyo as displayed in the following screenshot:
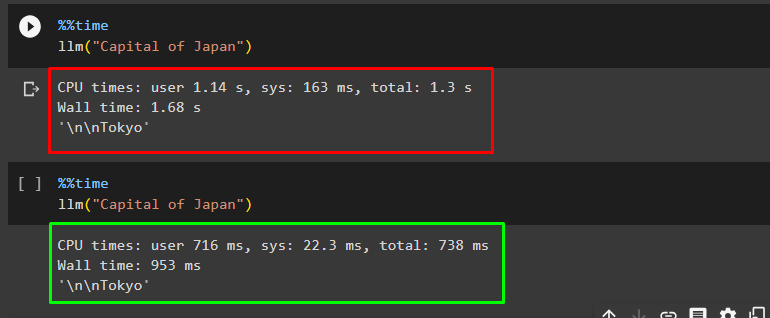
Again, run the same prompt to get the response from the GPT cache:
llm("Capital of Japan")
This time the execution time is much less, and the resource consumption also decreases vastly:
That’s all about using caching with LLMs using LangChain.
Conclusion
To work with the caching layer of Large Language Models using LangChain, simply install Langchain and all the modules required to get on with the process. Caching layers in LangChain are In-Memory Caching, SQLite Caching, and GPT Cache, etc. improving the performance of the model. This guide has demonstrated all the methods of working with caching layers of LLMs using LangChain.