
“The basic purpose of the fork command method is to create one or more child processes; the newly created child processes run concurrently with the parent process that created these child processes using fork statements. The next statement that is followed by the fork command will be executed by both child and parent processes simultaneously. The same CPU registers, the program counter (PC), and open files that the parent process accesses are used by the child process. The fork command doesn’t take any parameter as input, but it returns an integer value by using which we can easily identify whether either fork command created the child process successfully or not.”
Below is the list of values that are returned by the fork method:
- Negative Value: The process of creating a child process failed.
- Zero: The child process that was just created was returned.
- Positive Value: Returned to the caller or parent with a positive value. The newly generated child process’s process ID is contained in the value.
One thing to keep in mind is that fork is a threading method; therefore, to see the results; you must run the process on the local system. The fork command may require certain header or library files, such as sys/types.h and unistd.h. You must configure a Linux or UNIX-based operating system to run the program because the fork command cannot be used in a Windows environment. You must first confirm that the GCC compiler has been set up in the operating system environment. To accomplish this, we must first launch the terminal and then enter the command gcc —version, which displays the information that the gcc compiler of version 11.2.0 has been installed.

Before working on the C code snippets, you should maintain and update your system. The reason behind its update is to cater to the upcoming issues related to the newest versions of Linux. So, try out the below “update” query and make your Linux up to date.

Example 1
Let’s begin with the simplest and easiest program, in which we only use a single fork method and a straightforward print statement. The programs required header files that are listed in the first three lines of the code. The fork() method is called in the main method’s opening line. The fork command creates a child process that simultaneously executes the statement below. As a result, the print statement will appear twice on the shell screen when the program begins to run. Let’s begin writing the command in the environment of Ubuntu. We have to create the file using nano editor, but you can use your choice. Type the below command to create the new file:
nano forkThread.c
When the editor opens a file in editing mode, it is empty, so we must enter the code there before closing the file and saving it. The fork command must be preceded by a statement indicating that the child process will be started after this command. After the fork, the print statement will be run twice, once by the parent process and then by the newly established child process. This statement will only be executed once.
#include <sys/types.h>
#include <unistd.h>
int main() {
printf("Before the fork Method.\n");
fork();
printf("Child Process Created.\n");
return 0;
}
After saving and closing the forkThread.c file, we must now use the GCC compiler to compile the c file and create the output file using the command below.
gcc forkThread.c -o forkThread.out
The c file will be compiled by the GCC compiler, and the results will be saved to the forkthread.out file. However, if you don’t use the -o flag, the GCC Compiler will store the output to the a.out file, which is its default name, after compilation. The image shows how we can compile the C file using the above command.
![]()
The compilation results reveal that there were no syntax or semantic errors in our code, proving that it had been successfully compiled and that the output file had been successfully generated. You may view the results now that the output file has been executed. Just type the short command below to accomplish this:
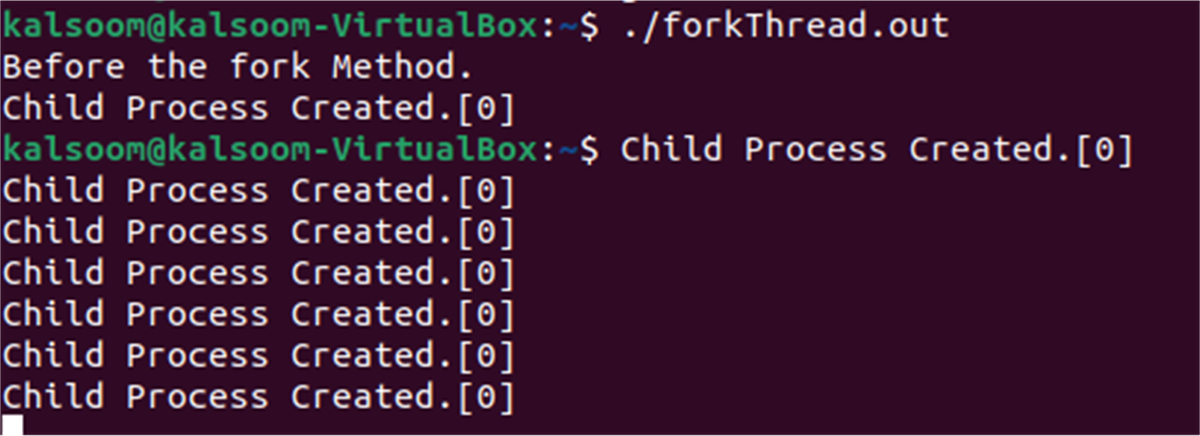
./forkThread.out

Example 2
In this example, we’ll count the instances in which a piece of code that contains numerous fork() lines are executed. We must write numerous fork methods and change the existing code. You should be aware that the number of times a piece of code is run depends on the power of 2, the number of times the fork statement has been written. For example, if the fork statement has been written three times, the code will be executed 2^3=8 times. Below is the snippet of the updated C code for a fork system call.
#include <sys/types.h>
#include <unistd.h>
int main() {
printf("Before the fork Method.\n");
int i = 0;
fork();
fork();
fork();
printf("Child Process Created: [%d]\n", i);
i++;
return 0;
}
In the code above, there are three fork statements, and before them, we’ve declared a variable “I” of the integer type that will be used to track the process each fork statement creates. This variable will also be incremented after each fork statement and before the return statement. Since the code has been modified, let’s recompile it using the GCC compiler. The output file is generated successfully.

As you can see, the variable “I” has not been increased in any way because the fork statement is immediately followed by a print statement that prints eight times, meaning that each fork statement contains a process that runs the aforementioned code simultaneously and only uses one copy of the program, preventing any increment from taking place in the code. There are a total of eight separate printing methods used to print the message below. As you can see, there is no increment. Because the child process only executes one print command.
Conclusion
That was all about using the C “Fork” system call. We have tried different illustrations to get different outputs, and different methods have been utilized. If you want to get a full grip on C “Fork” system call, try implementing the above two examples in various ways on your end, and you are good to go.