The World Wide Web is being used by almost every adult human in the world as it is the most popular information system. It uses hyperlinks to connect documents with each other so there are trillions of trillions of documents available on the internet. BeautifulSoup4 is the web scraping library in Python that is used to get data from the internet in the form of HTML, web pages or documents, and many more.
This guide will explain the process of using BeautifulSoup4 to load HTML in LangChain.
How to Use BeautifulSoup4 to Load HTML in LangChain?
To use the BeautifulSoup4 (BS4) to load HTML in LangChain, simply follow this guide with multiple steps to understand the process thoroughly:
Prerequisite: Install LangChain Modules
Before starting the process of loading HTML in LangChain using BS4, simply install the LangChain module via the following code:
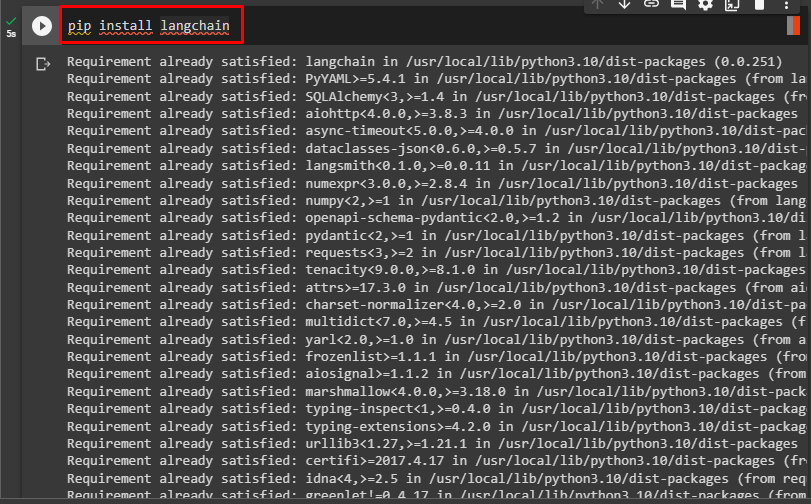
Another module is needed to install for loading unstructured data. It can be installed using the below code:
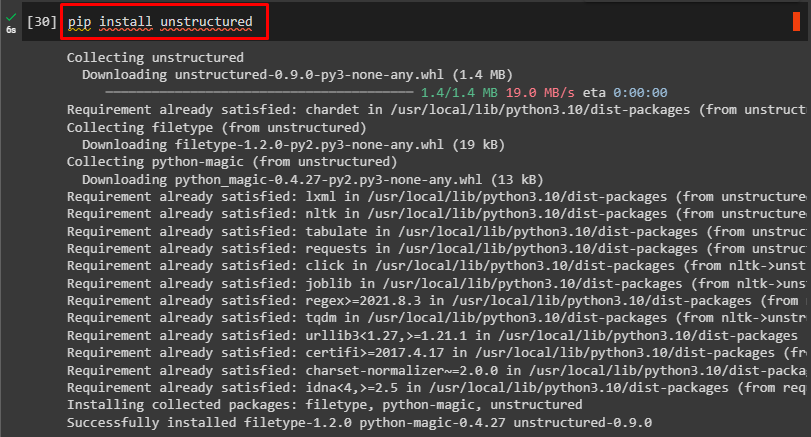
Upload HTML Data
After installing the required modules, simply use the following command to upload data from the local system to the cloud-based development environment:
upload = files.upload()
The following screenshot displays that the HTML file has been loaded successfully:

The HTML file loaded in this step has the following content:
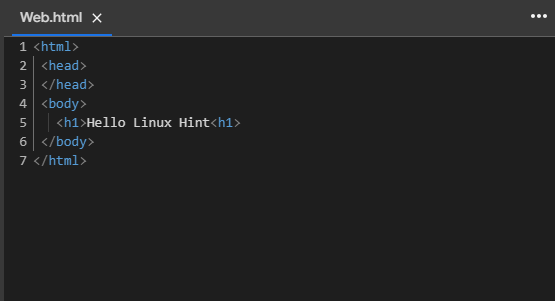
Let’s start with the first method to load the HTML in Langchain:
Method 1: Use BSHTMLLoader to Load the HTML
To import the BSHTMLLoader from the LangChain tool using the document_loaders library, follow the below code:
The following code uses the BeautifulSoup HTML loader to load the document and then prints the data variable containing the document:
data = loader.load()
data
The following screenshot displays the contents of the document with the metadata of the document using BeautifulSoup4:
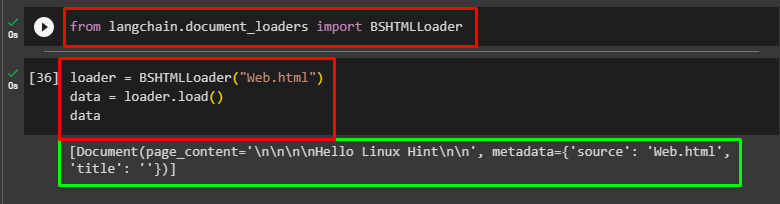
That is about using the BS4 to load HTML files in the LangChain framework.
Let’s head to another method of loading HTML files using the unstructured library:
Method 2: Use UnstructuredHTMLLoader to Load the HTML
After uploading the HTML file, simply use the following command to import UnstructuredHTMLLoader to load HTML documents:
Simply use the “loader” variable to use the document named “Web.html” uploaded to the IDE:
The following code is used to place the document contents in the data variable:
Running the above code will display that the tokenizer is unzipped to use the load() function:
Use the following command to return the contents of the HTML file:
The following screenshot displays the contents and metadata of the document placed in the data variable:

That’s all about using BeautifulSoup4 to load HTML files and documents in LangChain.
Conclusion
To use BeautifulSoup4 to load HTML in LangChain, install the LangChain framework on the integrated development environment. After that, upload HTML data from the local system and load it on LangChain using the “BSHTMLLoader”. Another method “UnstructuredHTMLLoader” can also be used to load data on the LangChain framework and get its metadata. This guide has explained the process of loading HTML documents in LangChain using the BeautifulSoup4 library.