The awk command is not just a command; it’s a scripting language, just like bash. The awk command is used for advanced pattern scanning, data extraction, and text manipulation. Because of its scripting support, it is useful for Linux power users, whether an administrator, a developer, or a Linux enthusiast. For instance, a system administrator can swiftly examine, i.e., log processing/analysis, tracking network IPs, generating reports, and monitoring system tasks.
If you are looking to have a strong grip on awk technically, this guide provides a brief tutorial on the awk command, including its use cases with examples.
awk Linux Command
The awk command contains programming language features. Because of its diverse use cases, awk has left behind its command-line competitors, i.e., grep, cut, etc. So, before diving further into the awk command examples, let’s first discuss the following:
- How is the awk command better than grep, cut, and other competitors?
- Syntax of the awk Command
- For what Operations can you use the awk command
How is the awk command better than grep, cut, and other competitors?
Let’s quickly have a look at why awk beats grep, cut, and other competitors.
- The awk command has built-in variables that are used silently by default. For instance, the “FS” allows you to split the field with some character, and you can access and perform operations on them.
- The awk supports loops, variables, conditions, arrays, and functions, which are not supported by any of the awk’s competitors.
- The data can be presented beautifully using the built-in variables that other commands do not have.
Syntax of the awk Command
The quotes on this command are optional. When using multiple patterns, actions, you need to put the quotes; otherwise, they are not necessary to be used every time. Here’s the further breakdown of the awk:
The “file” is the name of the file on which the “awk” is being applied. The ‘pattern {action}’ is the core part of awk:
- “pattern”: represents a condition, i.e., can be a regex, usually left blank to match all the lines.
- “action”: The operation to be executed after a successful pattern match.
For What Operations can you use the awk Command
The awk scripting language is broadly used in text processing. Let’s discuss what text processing operations can be performed using awk:
- Pattern scanning and processing.
- Text filtration, transformation, Editing/Modifying.
- Extracting data from fields or fields as a whole.
- File processing, i.e., single, multiple, supports different types of file processing
- Formatted output, i.e., getting output in another file, and print support
- Mathematical calculations, i.e., using conditions, looping support
- Controlled operation on the data, i.e., BEGIN, END
- System monitoring, i.e., using awk with other Linux commands to get the filtered results.
That’s all from understanding the basics of the awk command. Now, let’s dig into the examples to learn practically.
awk Command Examples
The awk examples provided here were experimented on two files, “students.txt” and “class.txt”.
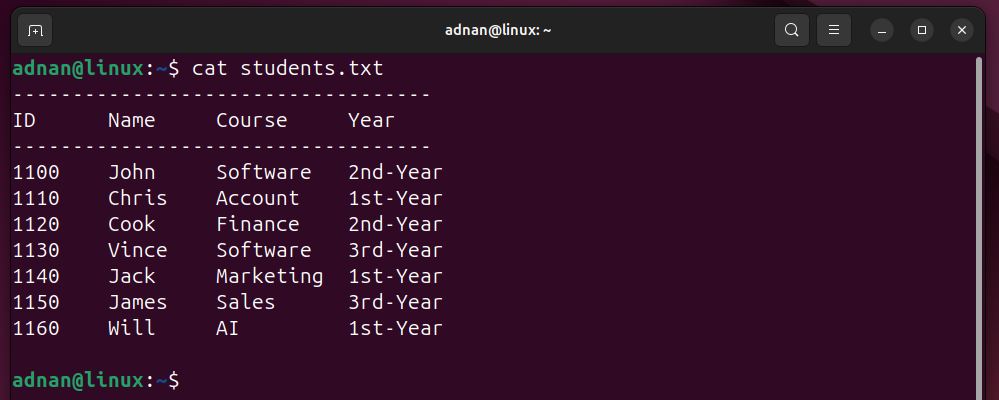
Content of the “students.txt”:
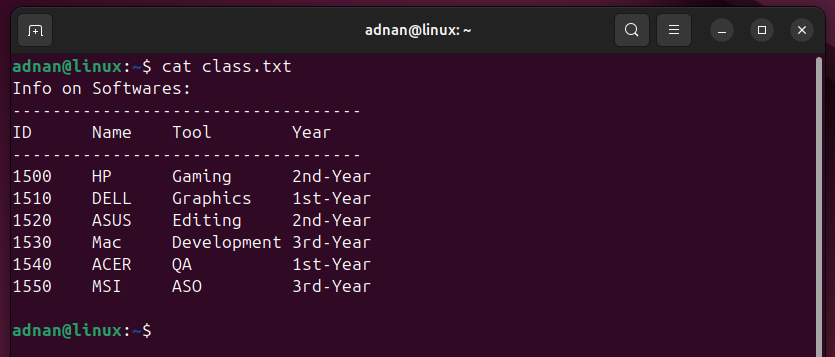
Content of the “class.txt”:
Let’s start with the basic use cases.
Print with awk
Print is the primary operation of awk command. It can be done anytime and in any form to print the data.
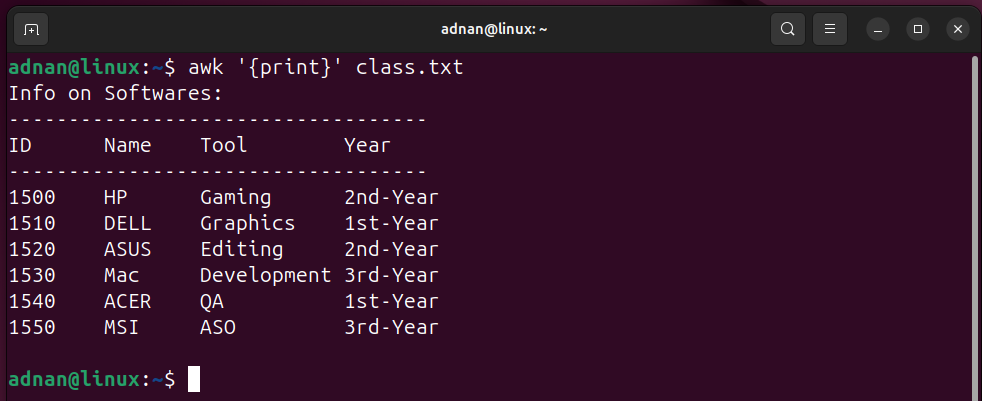
Example 1: Print All (in a single or multiple file)
Use the print in the “{action}” part to print the content of the file:
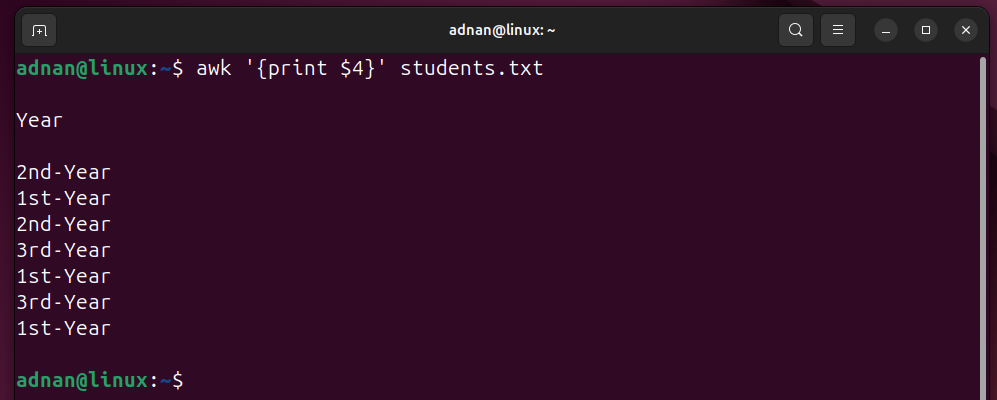
Example 2: Print Specific Columns
Write the column number in place of the “n” to show the data of that column only:
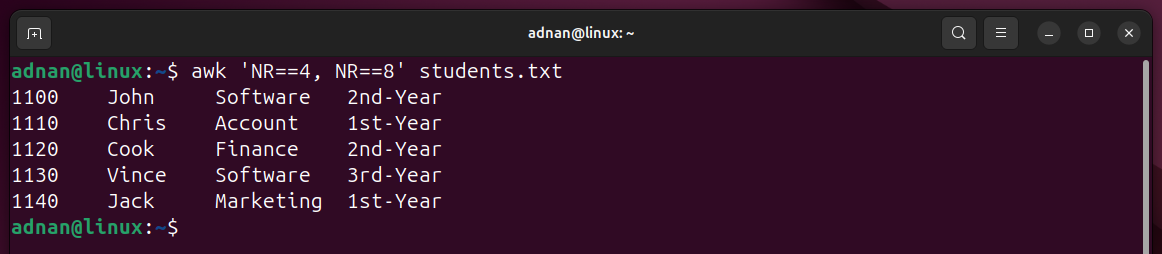
Example 3: Print a Specific Range of Data from the File
You can specify the column range to retrieve only that specific data:
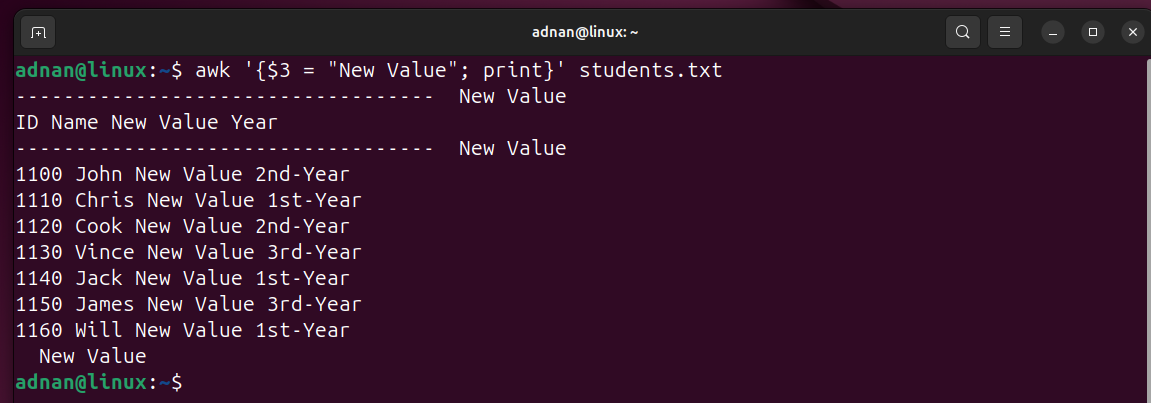
Example 4: Update any Field’s Value and Print it
You need to specify the field that you want to update and its value. Then, you can print it or store the output in some other file.
Here’s a demonstration:
Just updates on the terminal, the original content remains the same.
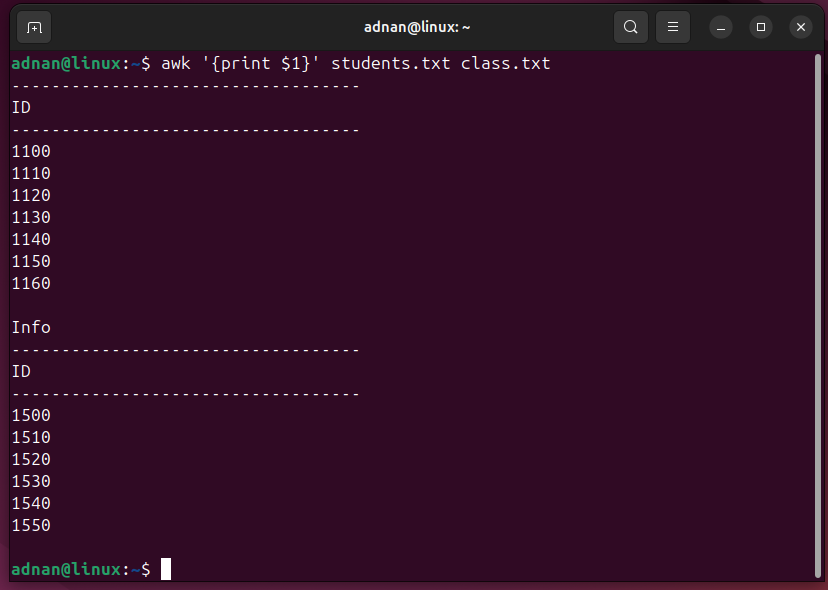
Example 5: Printing From Multiple Files
The awk command can be applied to multiple files. Here’s how it works:
The command will print the first column/field of two different files:
Matching a Specific Expression | awk With Regular Expressions
Expressions are used with the “awk” command to match a specific pattern or a word in the file and perform any operation on it.
Example 6: Matching the Exact Word
The command below matches the expression and performs the operation based on that match. Here’s a simple example:
The command checks for the “Software” word and prints all the data records that contain the “Software” word.

Example 7: Match the Start of the Character
The “carrot” symbol is used to match the character with the start of the files in the file and then further operations can be performed. Here’s the practical:
Printing the lines that start with “110”:

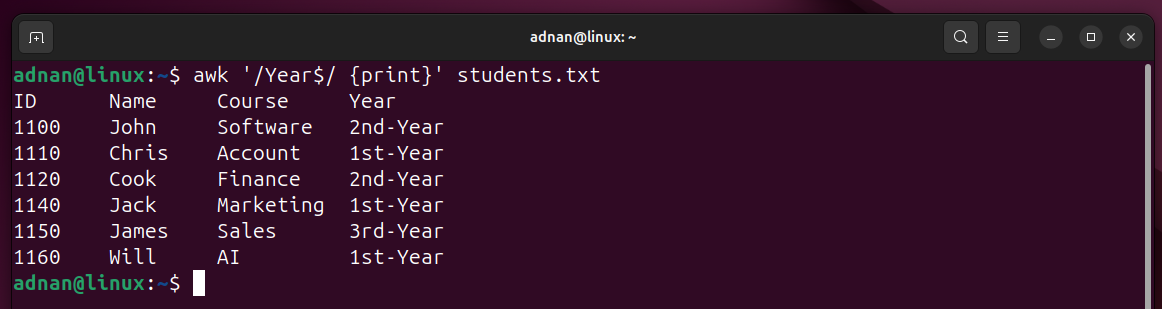
Example 8: Match the Endpoint Character
Likewise, the end character can also be specified to match and print (or perform any other operation):
The above command matches the “Year” and prints all the records that contain the word “year”.
Bonus: Other Regex Characters
The following are the rest of the Regex operators that can be used with awk to get more refined output:
| Regex Characters | Description |
|---|---|
| [ax] | Picks only a and x characters |
| [a-x] | Picks all the characters that are in the range of a-x. |
| \w | Selects a word |
| \s | Blank Space character |
| \d | Selects a digit. |
Formatting the Data With awk | awk Variables ( NR, NF, FS, FNR, OFS, ORS)
The awk variables are the built-in variables to process and manipulate the data. Each variable has its own purpose and refers to a record or a field. Let me first introduce all these variables to you:
NR (Number of Records):
The number of records being processed, i.e., if a file has 10 records (rows), then the NR’s value will range from 1 to 10.
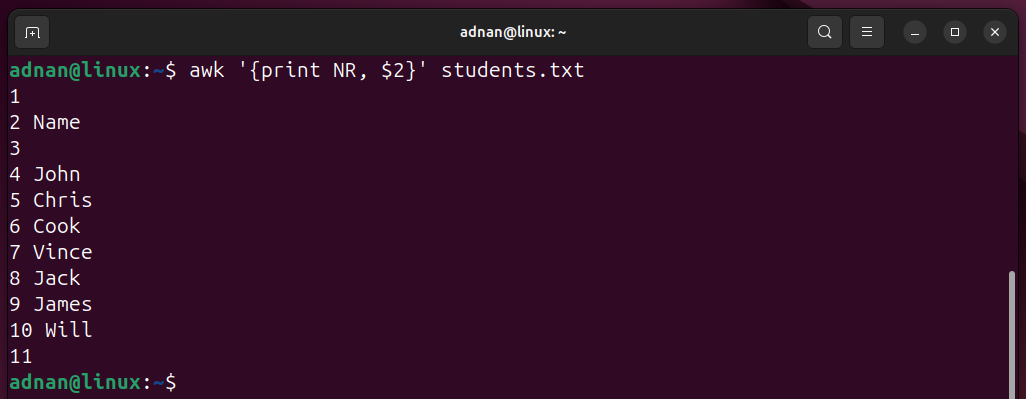
Example 9: Print the Number of Records
Printing the record number of the data in a file:
Example 10: Getting the Disk Usage Report
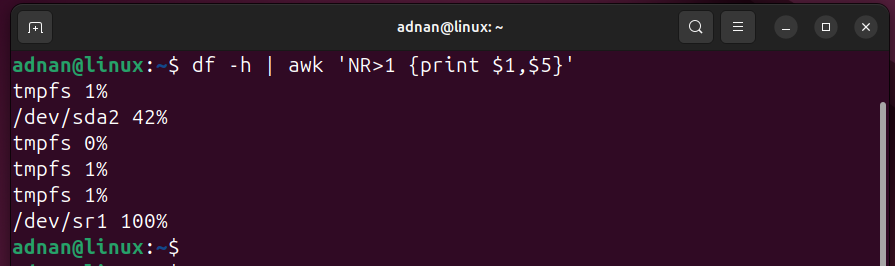
Based on NR, the administrator can analyze the disk usage report:
The command gets the input from the df -h command and then pipes it with awk to get the filesystem name ($1) and the percentage ($5) used by each filesystem.
Similarly, other resources’ performance and progress can also be checked using the NR in awk.
NF (Number of Fields):
Denotes the number of fields in each record.
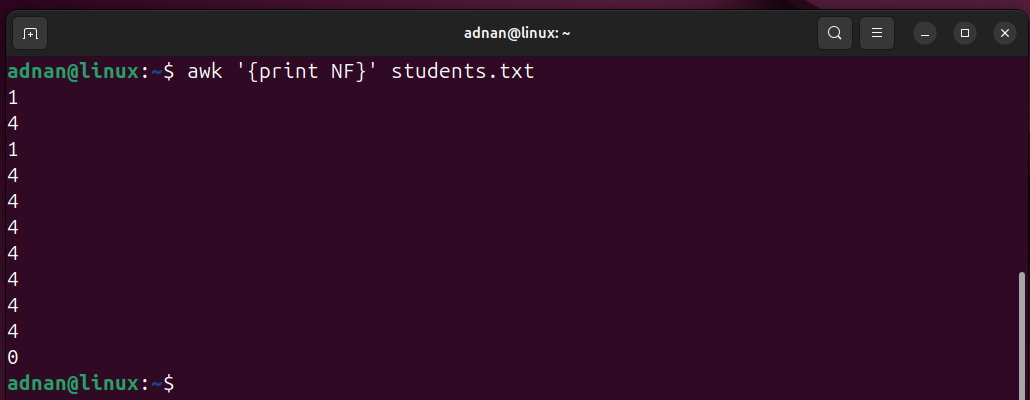
Example 11: Getting Number of Fields in a File
Let’s see it through the following:
The command prints the “NF” number of fields in each record of the target file:
FS (Field Separator):
This is the character used to separate the fields. It is a white space by default and a comma for an Excel file:
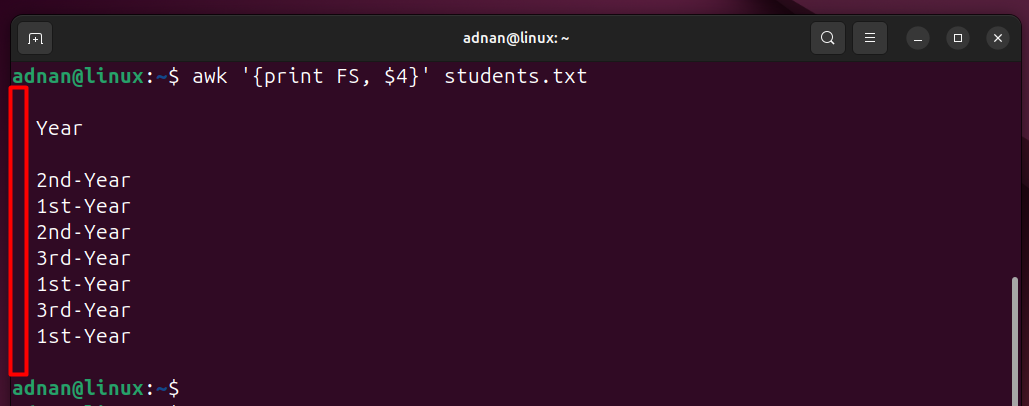
Example 12: Printing the field separator
This command prints the field separator:
FNR (File Number of Record):
Counting the number of records for each file when multiple files are being processed. For instance, when a single file is being processed, the NR value always starts from 1 and continues this number when multiple files are being processed, whereas the FNR value starts from 1 (for the new files) instead of continuing as NR.
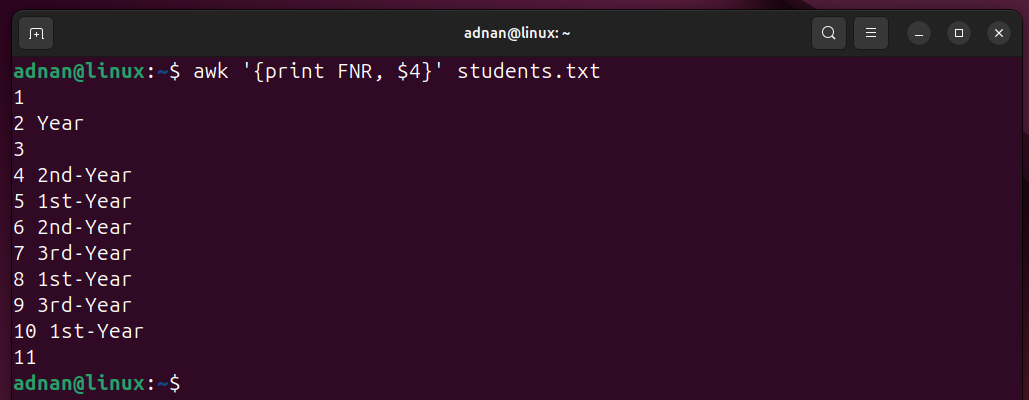
Example 13: Printing the Field Number Record with a Field
The command prints the field number and the 4th field:
OFS (Output Field Separator):
This is the Output field separator, i.e. the character separating the output fields. The default output field separator is a space ( “ ” ). However, you can change or set a new field separator with the help of the OFS keyword:
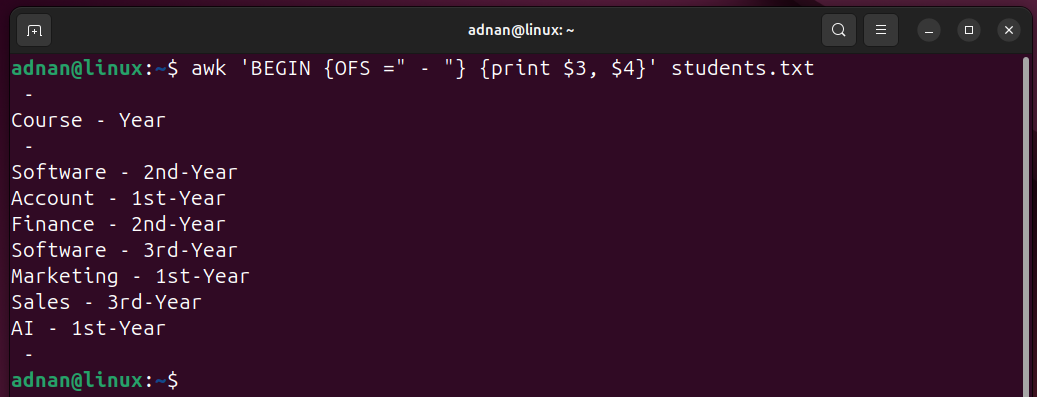
Example 14: Changing the Output Field Separator
Let’s understand it practically:
The command will print the 3rd and 4th columns from the specified file and will set the “–” as the new OFS:
ORS (Output Record Separator):
Likewise, OFS, this ORS represents the Output Record Separator. It is the space by default, however, you can change it as we are going to show you here practically.
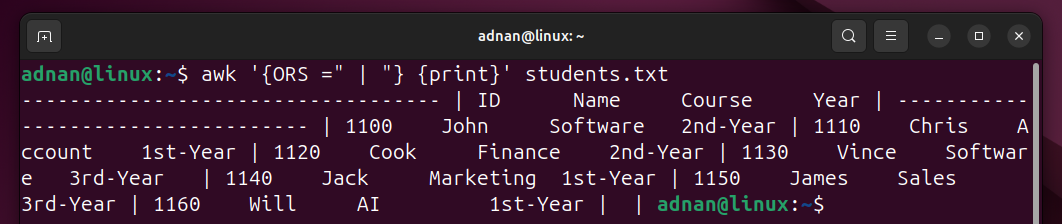
Example 15: Changing the Output Record Separator
The following command will change the record separator to “|”:
The record separator is now set to “ | ” for this specific output only.
Advanced awk Examples
Until now, we have gone through some basic and intermediate use cases of the awk example. Since awk also incorporates programming language features, so, here we’ll also discuss awk’s functionality with some advanced use cases:
Example 16: Find the Largest Field in a File
The following command uses the if-else statement to give you the length of the longest line in the file. Here’s an example to do so:
- The “awk” is the command keyword, and the “file” on which the operation is being performed. The rest of the details are in quotes.
- The length($0) expression gets the length of the current line and checks if it is greater than “max”.
- If the condition is true, the “length($0)” is stored in “max” and the “max” is printed at the end.

Similarly, if you want to check/get the minimum length of a line, then it would be:

Example 17: Get the Sum of the Field Values
With awk, you can calculate the sum of any field. Here’s the practical demonstration:
- A sum variable initially stores the first value from the first field ($1)
- The $1 (first field) values are being added to the already stored values in the sum.

Example 18: Finding a Max Value in a Column
Here, m is the variable that stores the maximum value:
Here’s the breakdown of the command:
- A variable “m” is initialized, then, if the value of the “2nd column” is greater than m, the “2nd column” value is stored in m.
- This continues until the condition “$2 > m” becomes false.

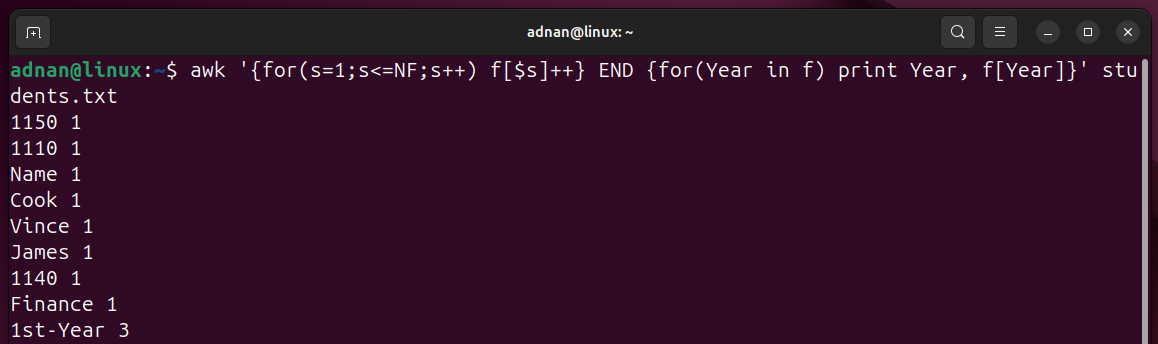
Example 19: Count Specific Occurrences of a Word
s is the looping variable, f shows the frequency, and “Year” word to be searched for the number of entries:
- The “for loop” loops through all in each record using (NF).
- The “f[$s]++” expression stores each word in an associative array “f” and counts how many times it appears.
- In the END block, the for loop prints each unique word and its frequency (as a value) from an array.
Example 20: Monitoring the Log Files
To monitor the Apache access log file:
Similarly, you can keep track of the iptables.log files to track the IPs triggering the firewall logs. You can check out / print the iptables.log for that purpose, i.e., available at the location /var/log/iptables.log.
Example 21: Search and Analyze | AWK with grep
The grep is known for its data filtering and searching, and the awk extracts and manipulates data. Let’s see the practical to check how these utilities work together:
Here’s the breakdown of the above command:
- grep “Software” will only filter and select the records containing the “Software” keyword.
- The awk command prints the columns containing the “Software” word.
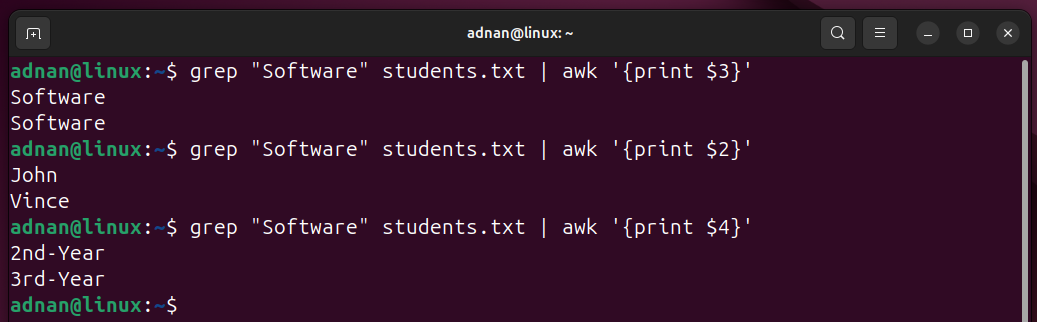
Similarly, grep and awk can be applied to other log files or system files to filter and analyze the specific log-related information.
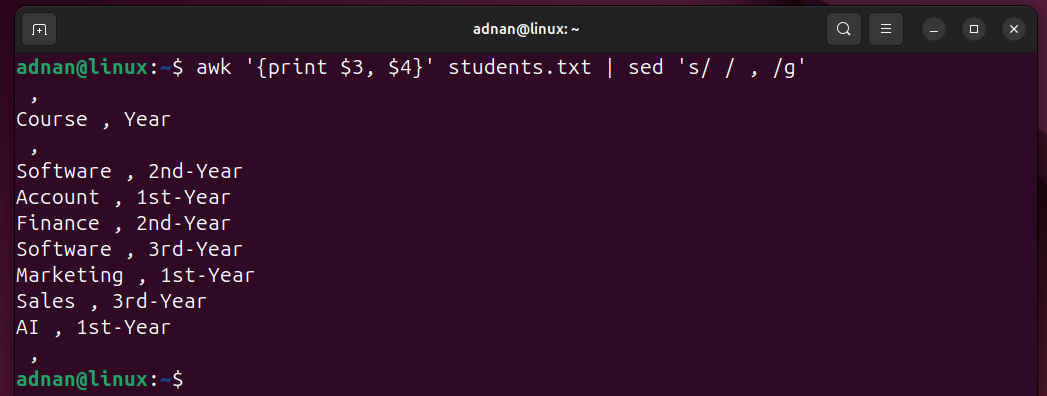
Example 22: Substituting | AWK with sed
The “sed” command edits and manipulates the text. So, the output of the awk command can be piped with the sed to perform specific operations on the output, or individually:
Let’ see the practical, using the following simple command:
The awk command prints the 3rd and 4th columns of the file, and the sed command substitutes the “,” in place of the white spaces in the document file globally.
Functions in awk
Since awk is a scripting language, it has a long list of functions that are used to perform various functions. Some of these are used in the above examples, i.e., length(n). Here, we will elaborate on a few functions and their use cases.
Substituting in awk with Functions
The awk has “sub” and “gsub” as two substitution functions; let’s understand these through examples:
Note: The file on which the “sub” and “gsub” functions will be experimented with.
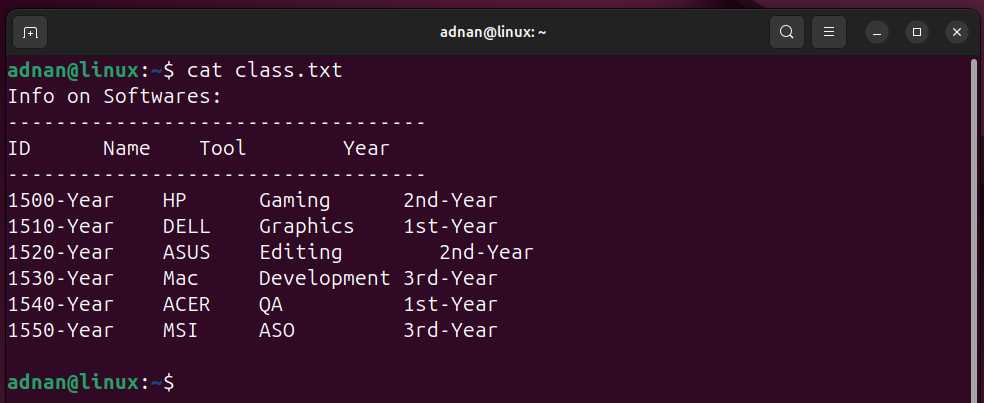
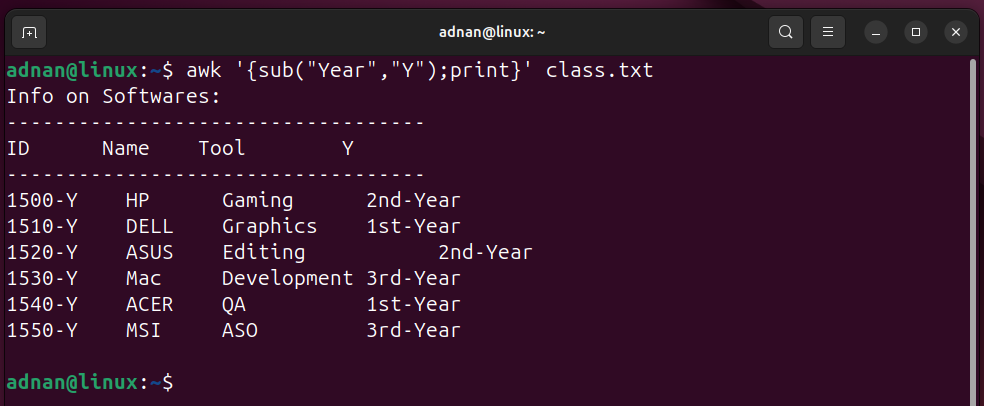
Example 23: Substitute the First Occurrence (in each record) Only | awk with sub
The “sub” function substitutes the first occurrence of the matching word/expression in each record. Here is an example command to understand:
The first occurrence of the word “Year” will be replaced with the “Y”:
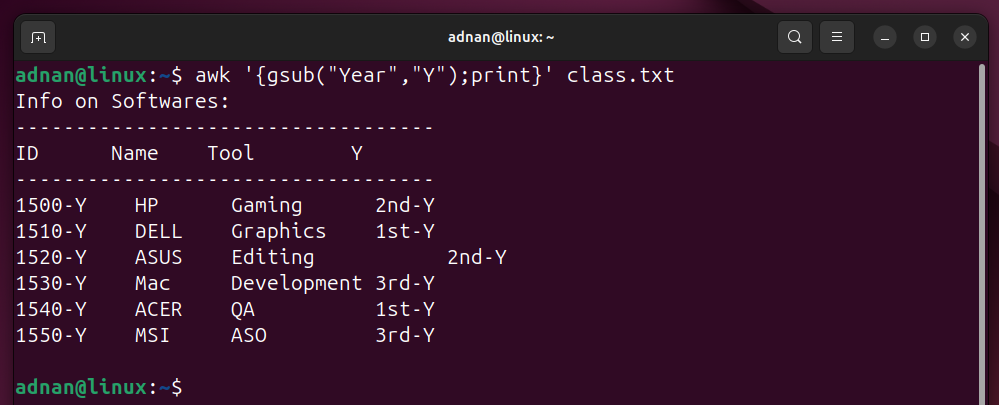
Example 24: Substitute all the instances of a word/Expression | awk with gsub
The “gsub” globally substitutes the matching keyword, i.e., all the occurrences of the matching keyword. Here’s an example:
Now, all the occurrences will be replaced:
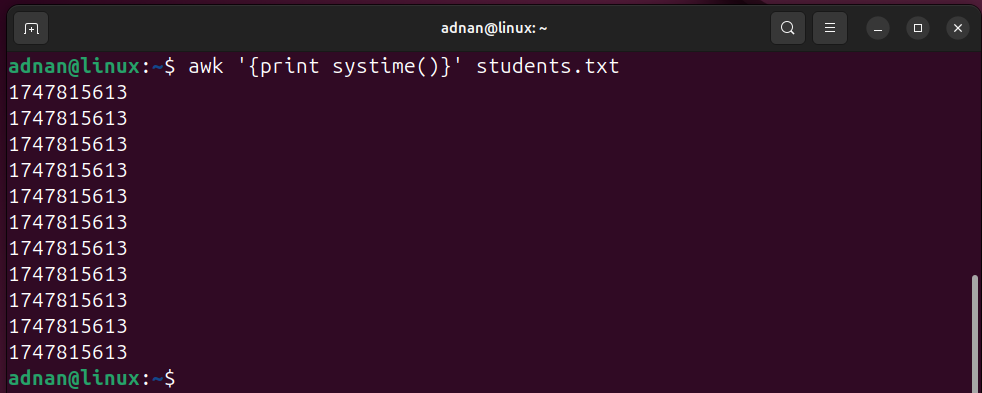
Example 25: Get the UNIX Timestamp | awk with systime()
The awk command has the systime() function to get the UNIX timestamp of the fields or for the whole system. Let’s practice it:
The command will print the UNIX timestamp for each of the records (when modified last time) of the file:
Similarly, you can get the overall UNIX time using the command:

Other awk Functions:
Because of its scripting support, the awk has a long list of supported functions. The following table lists some of these and also describes their purpose with syntax:
| awk Function | Description/Purpose | Syntax |
|---|---|---|
| length() | Length of the current line | awk ‘{print length()}’ file |
| substr(a, b, c) | Extracting a substring from string a, the length starts at b, and the overall length is c. | awk ‘{print substr($a, b, c)}’ file |
| split(a,b,c) | Split string a into array b using a separator c. | awk ‘{split($a, arr, “:”); print arr[a] }’ file |
| tolower(a) | Converts the a to lowercase | awk ‘{print tolower($a)}’ file |
| toupper(a) | Converts the a to uppercase | awk ‘{print tolower($a)}’ file |
| int(a) | Converts the $a into an integer | awk ‘{print int($a)} file’ |
| sqrt(a) | Square root of $a. | awk ‘{print sqrt($a)}’ file |
| srand() | Seeding a random generator | awk ‘BEGIN { srand(); print rand() }’ |
| rand() | Random generator |
That’s all from this tutorial.
Conclusion
The awk utility is an effective command-line tool that serves as a scripting language, too. From a basic search and find to running it for advanced scripting, the awk is a full package.
This post has a brief overview and explanation of the awk command in Linux, with advanced examples.
FAQs
Q 1: What does awk stand for?
The awk is named after its inventors, i.e., Aho, Weinberger, and Kernighan. They designed awk at AT&T Bell Laboratories in 1977.
Q 2: What is awk in Linux?
Ans: The awk is a powerful command-line utility and a scripting language. The awk is used to: read the data, search and scan for patterns, print, format, calculate, analyze, and more. For these use cases, awk sometimes has to be used with grep, sed, and normal regular expressions.
Q 3: What does awk ‘{print $2}’ mean?
The awk ‘{print $2}’ will print the 2nd (second) field of the file on the terminal. If used with multiple files, then the 2nd (second field of multiple files will be printed.
Q 4: What is the difference between awk and grep?
The grep performs the searching and filtering up to some extent, while the awk utility extracts, manipulates, and analyzes the data. The awk and grep are used together for search and analysis purposes, i.e., grep provides the searching/filtering support, where the awk performs the analysis.
Q 5: What is the difference between awk and bash?
Bash is recommended for professional scripting. However, where scripting and basic operations on the terminal are required, then awk is good. Both awk and bash are scripting languages. However, the simpler tasks are performed swiftly using awk as compared to bash.
Q6: How do I substitute using awk?
The awk supports two functions for substituting, i.e., sub and gsub. The sub is used to substitute the first occurrence of the matching word, whereas the gsub is used for global substitution of the matching word.