That overview is a bit in the abstract so let’s ground it in a real-world scenario, imagine you need to monitor several web servers. Each running its own website, and new logs are constantly being generated in each one of them every second of the day. On top of that there are a number of email servers that you need to monitor as well.
You may need to store that data for record keeping and billing purposes, which is a batch job that doesn’t require immediate attention. You might want to run analytics on the data to make decisions in real-time which requires accurate and immediate input of data. Suddenly you find yourself in the need for streamlining the data in a sensible way for all the various needs. Kafka acts as that layer of abstraction to which multiple sources can publish different streams of data and a given consumer can subscribe to the streams it finds relevant. Kafka will make sure that the data is well-ordered. It is the internals of Kafka that we need to understand before we get to the topic of Partitioning and Keys.
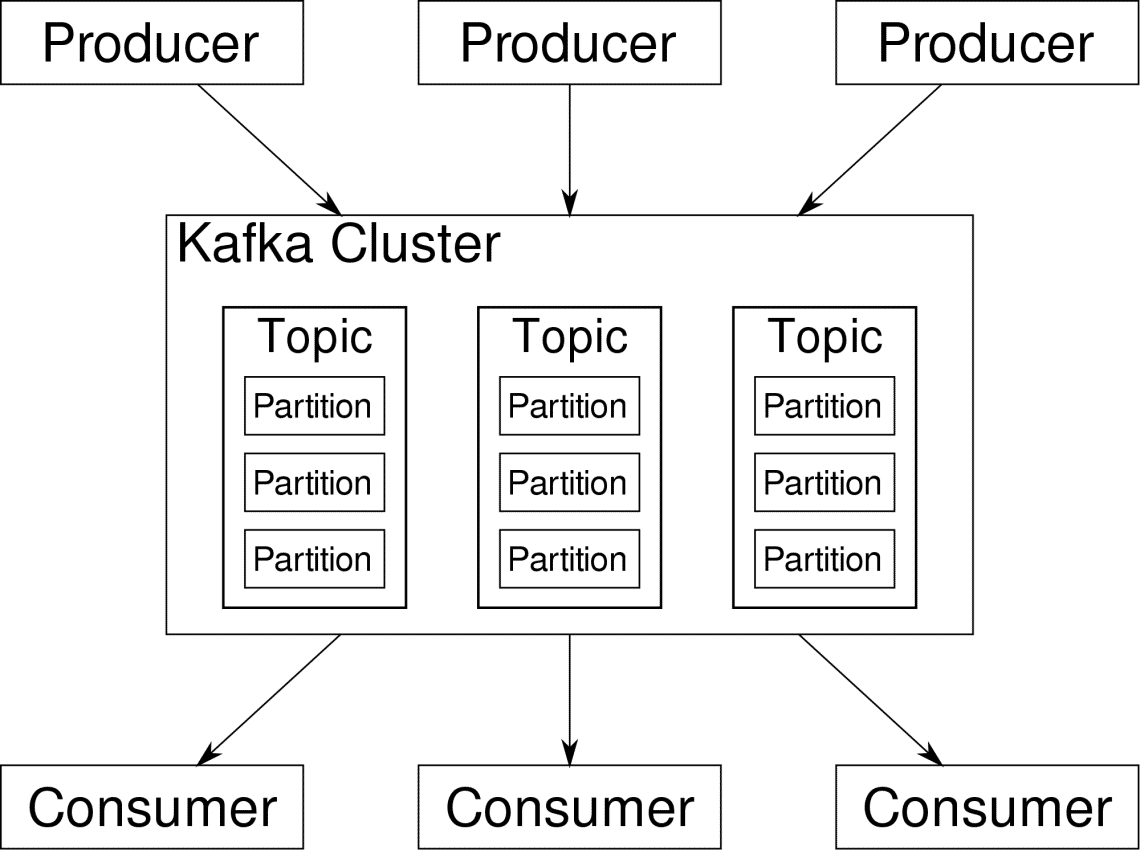
Kafka Topics, Broker and Partitions
Kafka Topics are like tables of a database. Each topic consists of data from a particular source of a particular type. For example, your cluster’s health can be a topic consisting of CPU and memory utilization information. Similarly, incoming traffic to across the cluster can be another topic.
Kafka is designed to be horizontally scalable. That is to say, a single instance of Kafka consists of multiple Kafka brokers running across multiple nodes, each can handle streams of data parallel to the other. Even if a few of the nodes fail your data pipeline can continue to function. A particular topic can then be split into a number of partitions. This partitioning is one of the crucial factors behind the horizontal scalability of Kafka.
Multiple producers, data sources for a given topic, can write to that topic simultaneously because each writes to a different partition, at any given point. Now, usually data is assigned to a partition randomly, unless we provide it with a key.
Partitioning and Ordering
Just to recap, producers are writing data to a given topic. That topic is actually split into multiple partitions. And each partition lives independently of the others, even for a given topic. This can lead to a lot of confusion when the ordering to data matters. Maybe you need your data in a chronological order but having multiple partitions for your datastream doesn’t guarantee perfect ordering.
You can use only a single partition per topic, but that defeats the whole purpose of Kafka’s distributed architecture. So we need some other solution.
Keys for Partitions
Data from a producer are sent to partitions randomly, as we mentioned before. Messages being the actual chunks of data. What producers can do besides just sending messages is to add a key that goes along with it.
All the messages that come with the specific key will go to the same partition. So, for example, a user’s activity can be tracked chronologically if that user’s data is tagged with a key and so it always end up in one partition. Let’s call this partition p0 and the user u0.
Partition p0 will always pick up the u0 related messages because that key tie them together. But that doesn’t mean that p0 is only tied up with that. It can also take up messages from u1 and u2 if it has the capacity to do so. Similarly, other partitions can consume data from other users.
The point that a given user’s data isn’t spread across different partition ensuring chronological ordering for that user. However, the overall topic of user data, can still leverage the distributed architecture of Apache Kafka.
Conclusion
While distributed systems like Kafka solve some older problems like lack of scalability or having single a point of failure. They come with a set of problems that are unique to their own design. Anticipating these problems is an essential job of any system architect. Not only that, sometimes you really have to do a cost-benefit analysis to determine whether the new problems are a worthy trade-off for getting rid of the older ones. Ordering and synchronization are just the tip of the iceberg.
Hopefully, articles like these and the official documentation can help you along the way.