In this article, we are going to learn about one of the important tasks of Ansible which is the “retry” task which we will list in the playbook to perform commands. We will learn how the retry task works in Ansible.
Retry is an Ansible task used to attempt to execute any problematic playbooks repeatedly. The Ansible output terminal will show the errors in that failure. Because of this, sometimes it difficult to grasp these issues when we try to fix them using Ansible. However, Ansible provides a “retry” option that allows us to perform the command more than once.
Take the scenario when we have a task in our playbook out of “all” hosts, some of the hosts are targeted because of certain task conditions their execution successful on the first attempt once the playbook has been executed. However, sometimes the remaining hosts will be successful on the second attempt at the task. Now, there are various methods where we may try to resolve this problem but also sometimes we might not have the time or system control to accomplish this.
Retrying the task in this situation might be the simplest and most effective course of action. The playbook will then be re-executed in a run failure state, and by default, it will keep attempting until it generates the desired result or stops reporting errors. We cannot claim that the Ansible retry option is a substitute for the standard loop that executes the job repeatedly until the condition is fulfilled. Thus, we are unable to use Ansible retry for tasks for which we have no way of predicting or estimating how long they would take. Therefore, this cannot possibly be a substitute for the standard loop. However, it avoids the severe issue of an infinite loop by timing out the work after a predetermined number of tries.
Prerequisites of Retry Tasks in Ansible
Practical examples of Ansible are provided in this session. We assume you have always had the following prerequisites if you intend to follow along when using the Ansible retry option:
- Before we can utilize the Ansible tool and implement the retry option, we require Ansible-related applications on your system. This tutorial makes use of Ansible 2.12 or a later version.
- Because of this, we need an Ansible controller to run the commands on remote hosts and the remote hosts that we would like to concentrate on for implementations.
Let us just go through the retry option idea in depth and look at how Ansible puts it into effect by using an example.
Example: Retrying the Tasks 5 Times in Ansible Playbooks
Before implementing the example, a thorough understanding of a variety of tasks contained in the Ansible configuration tool is a requirement for any aspiring Ansible master or skilled provider, such as an Ansible controller to make changes to the remote host device. Let us take the scenario where we try to implement the retry option. Here is the example in Ansible which we are going to implement to execute the tasks of the playbook multiple times.
To start implementing the commands, first, we will have to make the playbook by using the Ansible tool. Below is the statement which we will run to create the playbook in Ansible.
After writing the above command, the retries.yml playbook will be created and opened into a new Ansible terminal. In the playbook, we always define first the implementation that we are going to implement in the “name” parameter. Next, we will utilize the “hosts” parameter so that we can provide the IP address or related information of the remote host through which we are going to connect. We will use “localhost” as the target remote server in this example.
Using the Ansible “Gathering Facts” component, we will collect information about the targeted local host. This data is commonly described as “facts” or “parameters” in the Ansible software. By utilizing the particular command “setup” in the Ansible software, we can gather the information of localhost. However, Ansible playbooks generally call this setup parameter by default to accomplish the gathering facts parameter. We will either provide the value “true” or “false” to collect the data of the local host. As shown below in the playbook, we do not want to get the target localhost information, therefore we provided a “false” value to the gather_fact parameter.
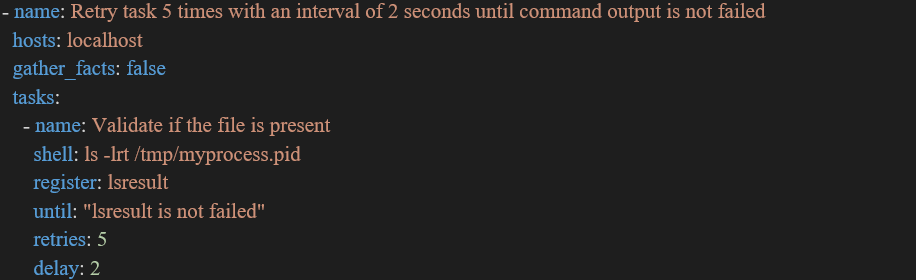
After declaring the parameters which will be required for the playbook to configure the local host device, we will list the tasks in the playbook which we want to implement on the local host machine. In the tasks list, we will first provide the name of the task that we are going to do, that is check the validity of the file is present or not in the localhost machine. We are using the Ansible shell parameter that executes the shell commands on the localhost device.
In Ansible, the shell parameter has a default path in which the /bin/sh executes commands, but in this example, we have given the “ls –lst /tmp/myprocess.pid” path where the Ansible controller made the changes in localhost device. Then, to monitor and save the output in this Ansible parameter, we utilized the “register” parameter.
Next, we used the “until” parameter that is used to retry the playbook tasks 5 times for 2 seconds. For defining the interval, we have used the default parameter of Ansible which is “delay” and the number of times the tasks of the playbook will run is in the “retries” parameter of Ansible.
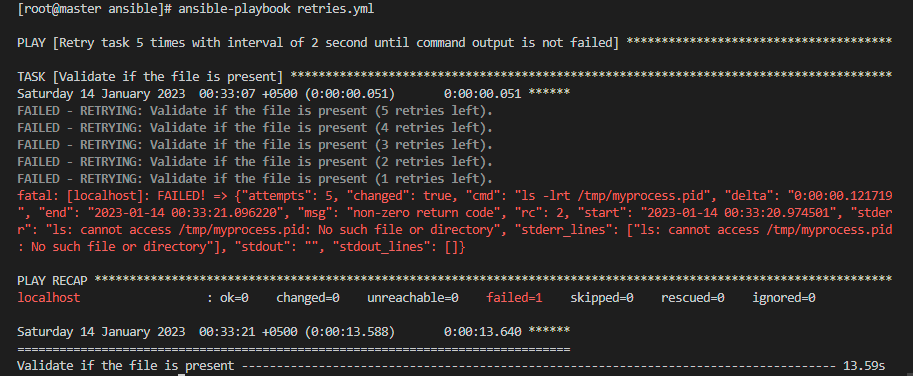
Now, we will terminate the retries.yml playbook by hitting Ctrl+X. Now, we want to run the playbook. So, we will use the command below:
We will get the outcome below after executing the command above. As shown in the output, the playbook is executed 5 times successfully with an execution time of 2 seconds.
Conclusion
This article has covered how the Ansible playbook’s retry parameter functions. We have thoroughly mastered the retry parameter theory. Then, to better understand the concept of retry, we put an example into practice.