Quick Outline
This post will demonstrate the following:
How to Use an Agent to Return a Structured Output in LangChain
- Installing Frameworks
- OpenAI Environment
- Creating a Retriever
- Building Tools
- Creating Prompt Template
- Customizing Parsing Logic
- Building Language Model
- Creating an Agent
- Running the Agent
How to Use an Agent to Return a Structured Output in LangChain?
To get an agent that can return a structured output in LangChain can be more useful or more understandable. The user often wants to get the output from the bots in order to understand some complex topic or data and the model needs to generate the output in such a way. To learn the process of using an agent to return a structured output in LangChain, simply go through the following output:
Step 1: Installing Frameworks
Get started with the process of extracting the structured output by installing the LangChain framework using the following code:
Use the vector store or database to store the information in the structured format by installing the chroma database using the pip command:
Split the data into smaller chunks using the tokenizers by installing the tiktoken tokenizer:
Now, install the OpenAI framework to build the language model for getting the structured output:
Step 2: OpenAI Environment
The next step after installing the modules is to set up the environment using the OpenAI’s API key:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
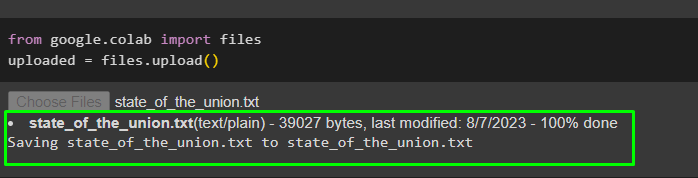
Load the data from the local system by executing the following code and clicking on the “Choose Files” button:
uploaded = files.upload()
The data set contains State of the Union addresses from 1989 to 2017 and it is available at Kaggle librray:
Step 3: Creating a Retriever
After loading the data from the computer, simply import the libraries for creating the embeddings by converting the text into numbers. Import text splitter to build chunks of the data and TextLoader to integrate the data uploaded in the previous step:
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
Apply the TextLoader() method with the name of the uploaded file and configure the size for the chunks to build the retriever for extracting the data:
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
for i, doc in enumerate(texts):
doc.metadata['page_chunk'] = i
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings, collection_name="state-of-union")
retriever = vectorstore.as_retriever()
Step 4: Building Tools
After that, import the “create_retriever_tool” for building the tools required to work with retrievers:
retriever_tool = create_retriever_tool(
retriever,
"sou-retriever",
"Ask queries to the retriever and get information about the dataset"
)
Step 5: Creating Prompt Template
Train the model by giving the structure of the input so the model can understand the question and display output according to the prompt:
from typing import List
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
class Response(BaseModel):
"""Final response to the question being asked"""
answer: str = Field(description = "The final answer to respond to the user")
sources: List[int] = Field(description="List of page chunks that contain answers to the question that only include a page chunk if it contains relevant information")
Step 6: Customizing Parsing Logic
Import the libraries like AgentActionMessage and AgentFinish to customize the parsing logic using the JSON format in the LangChian:
import json
Now, simply customize the output structure or parsing logic using the language model like llm for this process. The parse function returns the AgentFinish() method if there is no function called or the model does not have any response to generate. On the other hand, if there is some method or value to return, the model simply returns the AgentActionMessageLog() method:
if "function_call" not in output.additional_kwargs:
return AgentFinish(return_values={"output": output.content}, log=output.content)
function_call = output.additional_kwargs["function_call"]
name = function_call['name']
inputs = json.loads(function_call['arguments'])
if name == "Response":
return AgentFinish(return_values=inputs, log=str(function_call))
else:
return AgentActionMessageLog(tool=name, tool_input=inputs, log="", message_log=[output])
Step 7: Building Language Model
The next step needs multiple libraries to build the language model and then design or configure the agent:
from langchain.chat_models import ChatOpenAI
from langchain.tools.render import format_tool_to_openai_function
from langchain.agents.format_scratchpad import format_to_openai_functions
from langchain.agents import AgentExecutor
Train the model by applying the structure of the prompt by using the ChatPromptTemplate() method:
("system", "You are a helpful assistant"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
Finally, use the OpenAI() method to configure the llm model:
Step 8: Creating an Agent
Before getting the desired agent, configure the tools required for the agent to work in this process:
functions=[
format_tool_to_openai_function(retriever_tool),
convert_pydantic_to_openai_function(Response)
]
)
After building the model and tools for the agent, we have to design the agent we are going to use to return a structured output:
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps'])
} | prompt | llm_with_tools | parse
Once the agent is built, simply call the AgentExecutor() method with the tools, agent, and verbose as its arguments:
Step 9: Running the Agent
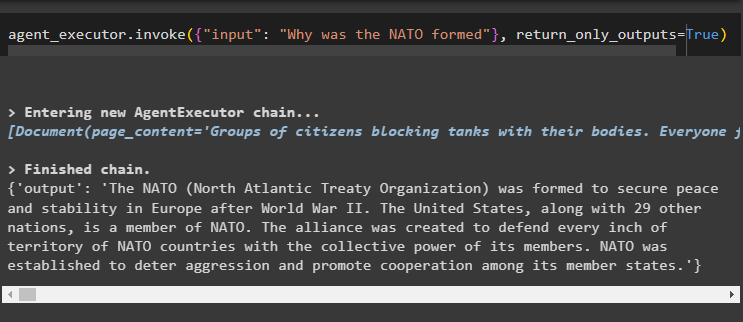
Now, simply run the agent_executor with the value of the input to get the output with the number of resources:
The output structure provides the clear output of the question with the number of sources that can be websites on the internet, etc:
That’s all about how to use an agent to return a structured output in LangChain.
Conclusion
To use an agent to return a structured output in LangChain, simply install modules like chromadb, tiktoken, etc. to build the agent. Set up the environment using the API key and build the language model by calling the OpenAI() method. Also, configure the prompt template, tools, and agent before calling the agent_executor() method to get the structured output. This guide has elaborated on the process of using an agent to return a structured output in LangChain.