Before moving to the methods, we will create PySpark DataFrame.
Example:
Here, we are going to create PySpark dataframe with 5 rows and 6 columns.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:

Method 1: Add New column with values using withColumn()
We can add new column from an existing column using the withColumn() method.
Syntax:
Parameters:
- new_column is the column.
- col() function is used to add its column values to the new_column.
Example:
In this example, we are going to create new column – “Power” and add values to this column multiplying each value in the weight column by 10.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#Add column named Power
#from the weight column multiplied by 2
df=df.withColumn("Power",col("weight")* 2)
#display modified dataframe
print(df.collect())
#lets display the schema
df.printSchema()
Output:
root
|-- address: string (nullable = true)
|-- age: long (nullable = true)
|-- height: double (nullable = true)
|-- name: string (nullable = true)
|-- rollno: string (nullable = true)
|-- weight: long (nullable = true)
|-- Power: long (nullable = true)
Method 2: Add New column with None values using withColumn()
We can add new column with None values using the withColumn() method through lit() function.
Syntax:
Parameters:
- new_column is the column.
- lit() is a function used to add values to the column.
Example:
In this example, we are going to create new column – “Power” and add None values to this column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit functions
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#Add column named Power
# with None values
df=df.withColumn("Power",lit(None))
#display modified dataframe
print(df.collect())
Output:
Method 3: Add New column with values based on condition using withColumn()
We can add new column with conditions using the withColumn() method and values through lit() function. We can specify the conditions using when() function. this can be imported from pyspark.sql.functions.
Syntax:
.when((condition) , lit("value2"))
…………………………………
. when((condition) , lit("value n"))
.otherwise(lit("value")))
Parameters:
- new_column is the column.
- lit() is a function used to add values to the column.
- when() will take condition as input and add values based on the criteria met.
- otherwise() is the laststep which will execute any of the above conditions not met the criteria.
Example:
In this example, we are going to create new column – “Power” and add values from the age column.
- add Low value if the age is less than – 11
- add High value if the age is less than or equal to – 12 and greater than or equal to – 20
- Otherwise add High value
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit,when functions
from pyspark.sql.functions import col,lit,when
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#add a column - Power
#add column vales based on the age column
#by specifying the conditions
df.withColumn("Power", when((df.age < 11), lit("Low"))
.when((df.age >= 12) & (df.age <= 20), lit("Medium"))
.otherwise(lit("High"))).show()
Output:

Method 4: Add New column with values using select()
We can add new column from an existing column using the select() method.
Syntax:
Parameters:
- new_column is the column.
- lit() function is used to add column values to the new_column.
Example:
In this example, we are going to create new column – “Power” and add values to this column multiplying each value in the weight column by 10.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit functions
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
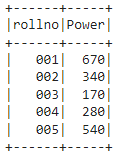
#add column named - Power from weight column
# add values by multiplying with 10
df.select("rollno", lit(df.weight * 10).alias("Power")).show()
Output:
Method 5: Add New column with None values using select()
We can add new column with null values using the select() method.
Syntax:
Parameters:
- new_column is the column
- lit() function is used to add None values
Example:
In this example, we are going to create new column – “Power” and add None values to this column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit functions
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
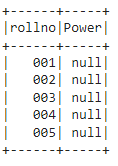
#add column named - Power
# add Null values with None
df.select("rollno", lit(None).alias("Power")).show()
Output:
Conclusion
In this tutorial, we discussed how to add a new column using select() and withColumn() functions. We have observed that lit() is the function that is used to add values to the new column. Finally, we discussed how to add None/Null values and the values from the existing columns to the PySpark DataFrame.