This guide will illustrate the process of adding memory to a chain with multiple inputs in LangChain.
How to Add Memory to a Chain With Multiple Inputs in LangChain?
The memory can be added to the LLMs or chatbots to store the most recent messages or data so the model can understand the context of the command. To learn the process of adding memory to a chain with multiple inputs in LangChain, simply go through the following steps:
Step 1: Install Modules
First, install the LangChain framework as it has a variety of dependencies to build language models:
Install the chromadb to store the data used by the memory in the Chroma vector store:
Tiktoken is the tokenizer used to create small chunks of large documents so they can be managed easily:
OpenAI is the module that can be used to build chains and LLMs using the OpenAI() method:
Step 2: Setup Environment and Upload Data
The next step after installing all the required modules for this process is setting up the environment using the API key from the OpenAI account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Upload the documents using the files library to build the chains in the LangChain framework:
uploaded = files.upload()
Step 3: Import Libraries
Once the document is uploaded successfully, simply import the required libraries from the Langchain module:
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
Step 4: Building Memory Using Chroma Database
Now, start building the vector space to store the embeddings and tokens of the document uploaded earlier:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
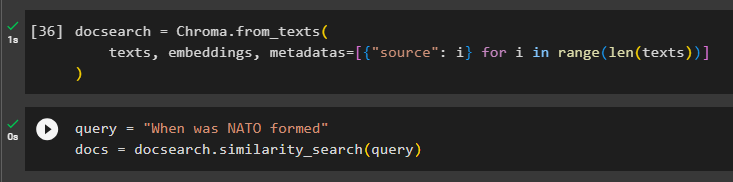
Configure the Chroma database for storing the text and embeddings from the document:
texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
)
Test the memory by asking the command in the query variable and then execute the similarity_search() method:
docs = docsearch.similarity_search(query)
Step 5: Configuring Prompt Template
This step explains the process of configuring the template for the prompts by importing the following libraries:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
After that, simply configure the template or structure for the query and run the chain once the memory is added to the model:
Given the chunks extracted from a long document and a question, create a final answer
{context}
{hist}
Human: {input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["hist", "input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="hist", input_key="input")
chain = load_qa_chain(
OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
)
Step 6: Testing the Memory
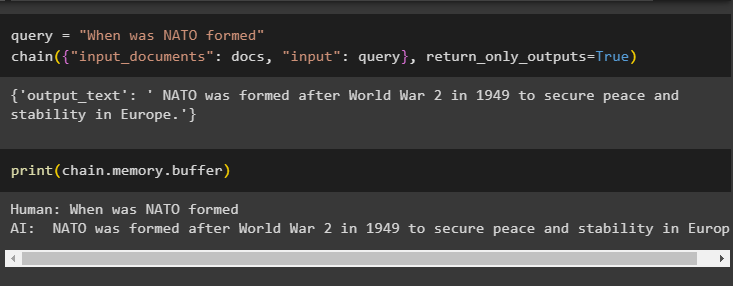
Here is the time to test the model by asking the question using the query variable and then executing the chain() method with its parameters:
chain({"input_documents": docs, "input": query}, return_only_outputs=True)
Print the data stored in the buffer memory as the answer given by the model is stored recently in the memory:
That is all about adding memory to a chain with multiple inputs in LangChain.
Conclusion
To add memory to a chain with multiple inputs in LangChain, simply install the modules and vector store to store the text and embeddings. After that, upload the data/document from the local system and then import the required libraries for storing the data to build the memory for the LLM. Configure the prompt template to store the most recent messages in the buffer memory and then text the chain. This guide has elaborated on the process of adding memory to a chain with multiple inputs in LangChain.