List of Contents:
- Create a New File
- Check the Existence of a File
- Read a File Using the “For” Loop
- Read a File Using the “While” Loop
- Calculate the Size of a File
- Append the Content into a File
- Make a Copy of a File
- Move the File Location
- Count the Total Lines of the File
- Search the Content in a File
- Search and Replace the Content of a File Using Regex
- Delete a File
Create a New File
Multiple ways exist in Bash to create a new file in Bash. New files can be created from the terminal using different types of text and GUI editors. The method of creating a new file from the terminal using the Bash “cat” and “echo” commands is shown in this part of the tutorial. Then, the file creation is shown using the nano editor.
Run the following command to create a text file named “courses.txt”:
Type the following content in the terminal:
CSE-106 Object-oriented programming
CSE-208 Visual programming
CSE-303 Advanced DBMS
CSE-407 Unix programming
Press “Ctrl+d” to stop writing and go to the command prompt.
Now, run the following command to check the content of the file:

Run the following command to create a file of a simple text:
Next, run the “cat” command to check the content of the “text.txt” file.
The following output appears after executing the previous commands:

Run the following command to open the nano editor to create a text file named “course-teacher.txt”:
Type the following content in the editor:
CSE-208 Saima Akter
CSE-303 Mahmuda Ferdous
CSE-407 Sabrina Sultana
Press “Ctrl+x” to save and exit from the editor.
Run the following command to check the content of the file:

Check the Existence of a File
The “-f” option is used to check the existence of the regular file and the “-s” option is used to check the existence of the non-empty file. If the file exists and contains a data, a message is printed to inform that the file exists and contains a data. Otherwise, a message is printed to inform that the file is empty or does not exist.
read -p "Enter an existing filename: " fn
#Check whether the file exists with data or not
if [ -f "$fn" ]
then
if [ -s "$fn" ]
then
#Print a message if the file is not empty
echo "$fn file exists and contains data."
else
#Print a message if the file is empty
echo "$fn file is empty."
fi
else
#Print a message if the file does not exist
echo "$fn file does not exist."
fi
The “courses.txt” file is created earlier that contains the data. So, the following output appears if the script is executed with the “courses.txt” filename:

According to the following output, the “t.txt” file exists and the file is empty:

According to the following output, the “course.txt” file does not exist in the current location:

Read a File Using the “For” Loop
Any existing file can be read using different loops in Bash. The following script shows the use of the “for” loop to read the content of a file where the filename is given as the command-line argument value. The IFS variable is used in the script to detect the new line of the file. The “cat” command is used inside the “for” loop to read the content of the file line by line. The “$counter” variable is used to print the line number with each line of the file.
#Initialize the filename from the command-line argument
fn=$1
#Initialize counter
counter=1
#Set the internal field separator
IFS=$'\n'
#Read the file line by line
for val in $(cat "$fn")
do
#Print each line of the file with the line number
echo "Line-$counter: $val"
#Increment the counter
((counter++))
done
According to the output, the “cat” command is used to check the original content of the “courses.txt” file before executing the script. Then, the script is executed by giving the “courses.txt” as the first command-line argument value.
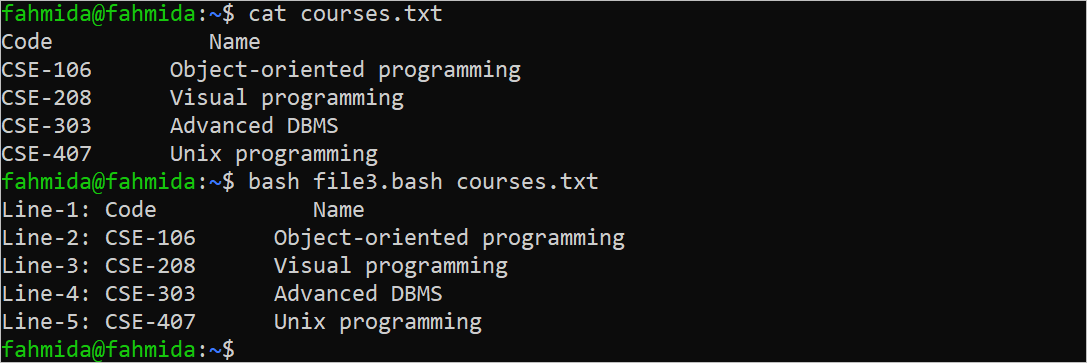
Read a File Using the “While” Loop
The following script shows the use of a “while” loop to read the content of a file where the filename is given as the command-line argument value. The “$counter” variable is used in this script also to print the line number with each line of the file.
#Initialize the counter
counter=1
#iterate the loop to read the file line by line
while read -r line
do
#Print each line with the line number
echo "Line-$counter: $line"
#Increment the counter
((counter++))
#Read the filename from the command-line argument
done < "$1"
The output of the provided script is similar to the previous example.
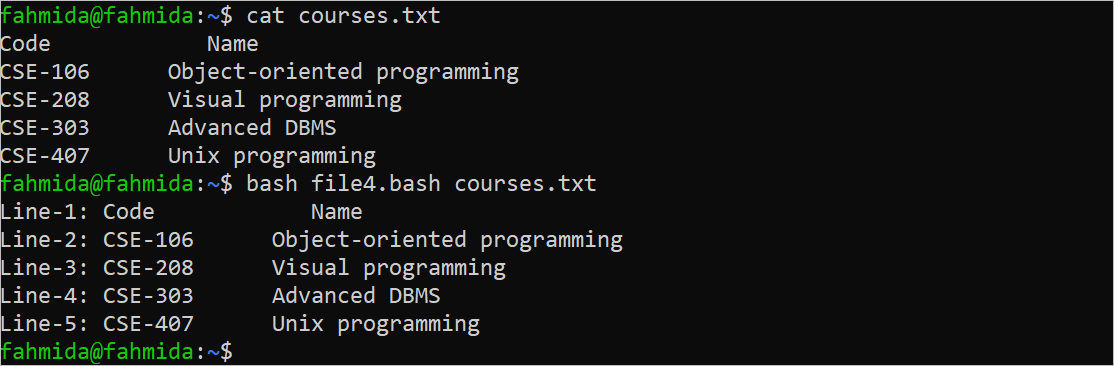
Calculate the Size of a File
The size of the file can be calculated in different ways using a Bash script. In the following script, the “stat” command with the “-c” option is used to calculate the size of the file in bytes. The filename is taken from the user. The size of the file is printed if the file exists and is non-empty. Otherwise, an error message is printed.
#Take the filename from the user
read -p "Enter an existing filename: " fn
if [ -s $fn ]
then
#Count the size of the file
size=$(stat -c %s $fn)
#Print the file size in bytes
echo "The size of the $file file is $size bytes."
else
echo "File does not exist or empty."
fi
The following output appears after executing the previous script. Here, the size of the “courses.txt” file is 153 bytes:

Append the Content into a File
The “>>” operator is used in Bash to append the content of the file. Suppose you have to add a new line in the “courses.txt” file using the “echo” command. Run the “cat” command before and after executing the “echo” command that adds a new line at the end of the “courses.txt” file.
$ echo "CSE-202 Data Structure" >> courses.txt
$ cat courses.txt
The following output appears after executing the previous commands. A new line is added at the end of the “courses.txt” file:
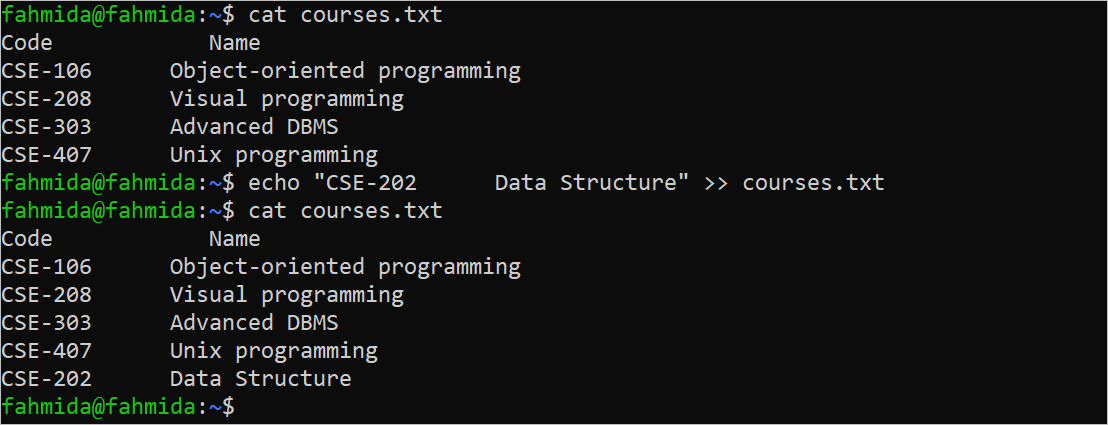
Make a Copy of a File
The “cp” command is used to create a new file from an existing file. The following script creates a new file named “courses_copy.txt” by copying the content of the “courses.txt” file:
#Define the source and destination filename
source_file="courses.txt"
destination_file="courses_copy.txt"
if [ -f $source_file ]
then
#Copy the file if exists
cp $source_file $destination_file
echo "File is copied successfully."
else
echo "Source file does not exist."
fi
The following output appears if the “copy.txt” file exists in the current location. Next, the “cat” command is executed to check whether the content of the file is copied properly or not:
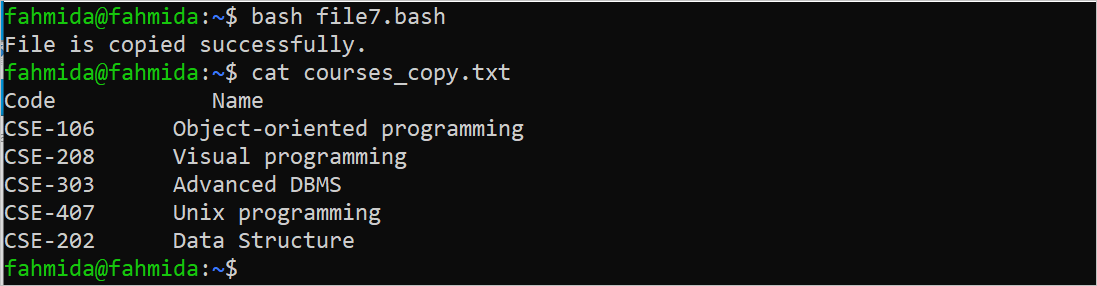
Move the File Location
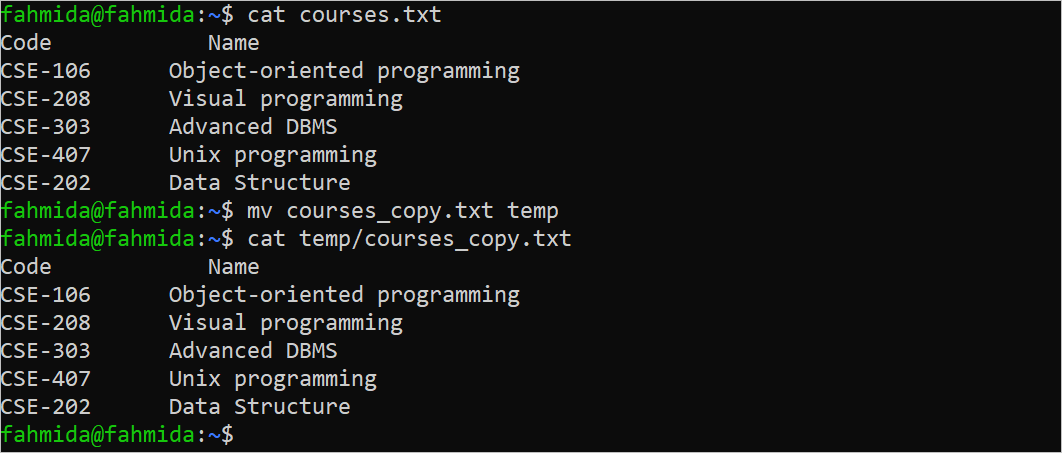
The “mv” command is used to move any file from one location to another location. Run the following commands to check the content of the “courses_copy.txt” file, move the file to the “temp” location, and check whether the file is moved successfully or not:
$ mv courses_copy.txt temp
$ cat temp/courses_copy.txt
The following output shows that the “courses_copy.txt” file is moved successfully to the “temp” folder:
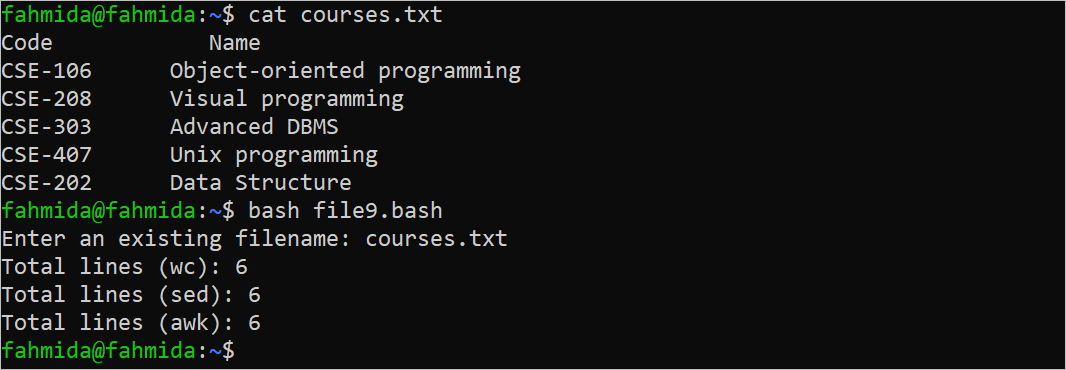
Count the Total Lines of the File
Multiple commands exist in Bash to count the total lines. In the following script, the “wc”, “sed”, and “awk” commands are used to count the total lines of the file that will be taken from the user. If the filename that is taken from the user does not exist, an error message is printed.
#Take the filename from the user
read -p "Enter an existing filename: " fn
if [ -s $fn ]
then
#Count total lines of the file using `wc`, `sed`, and `awk` commands
wc_lines=$(wc -l < $fn)
sed_lines=$(sed -n '$=' $fn)
awk_lines=$(awk 'END { print NR }' $fn)
#Print the output of different commands
echo "Total lines (wc): $wc_lines"
echo "Total lines (sed): $sed_lines"
echo "Total lines (awk): $awk_lines"
else
#Print a message if the file does not exist or is empty
echo "File does not exist or empty."
fi
The following output shows that the output of three commands that are used in the script are the same and the “courses.txt” file contains six lines:
Search the Content in a File
The “grep” command is used to search any content in a file using the search words or the regular expression pattern. The method of searching the content in a file using a particular searching word in the “grep” command with the “-i” option is shown in the following script. Here, the “-i” option indicates the ignore case. So, the searching word is searched in the file in a case-insensitive way.
#Take the filename from the user
read -p "Enter an existing filename: " fn
#Take the search word from the user
read -p "Enter the search word: " src
if [ -s $fn ]
then
#Search the particular word in the file
output=$(grep -i $src $fn)
if [ "$output" != "" ]
then
#Print the output of the `grep` command
echo "$output"
fi
else
#Print a message if the file does not exist
echo "File does not exist or empty."
fi
The following output appears after executing the script with the “courses.txt” filename, and the CSE-208 searching word. The second line of the file contains the “CSE208” word:

Search and Replace the Content of a File Using Regex
The “sed” command is one of the ways to search and replace the content of a file in Bash. In the following script, the method of searching and replacing the content of a file using the “sed” command with the “-i” option is shown. The filename, searching word, and replacing word are taken from the user.
read -p "Enter an existing filename: " fn
#Take the search word
read -p "Enter the search word: " src
#Take the replace word
read -p "Enter the replace word: " rep
if [ -s $fn ]
then
#Search and replace the particular word in the file
sed -i "s/$src/$rep/" $fn
else
#Print a message if the file does not exist
echo "File does not exist or empty."
fi
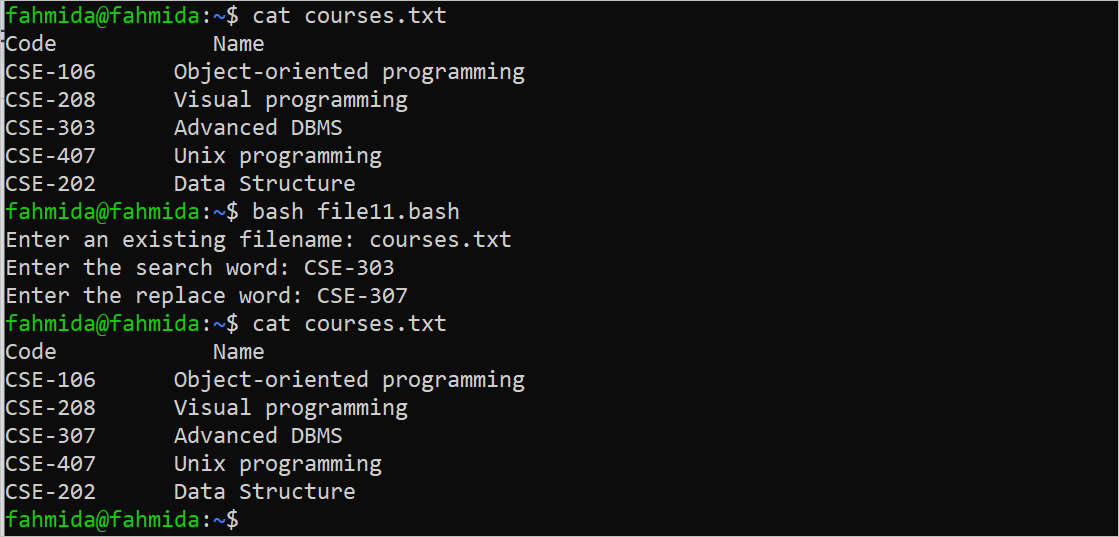
Run the following output to check the content of the “courses.txt” file before and after executing the script:
$ bash file11.bash
$ cat courses.txt
The following output shows that the CSE-303 search word exists in the “courses.txt” file and it is replaced by the CSE-307 replacing word:
Delete a File
The “rm” command is used to delete a file in Bash. This command is used with the “-i” option in the following script to remove a file if it exists. Here, the filename is taken from the user.
# Take the filename
read -p 'Enter the filename: ' fn
# Check the existence of the file
if [ -f $fn ]; then
# Remove the file
rm -i "$fn"
# Check whether the file is removed or not
if [ -e fn ]; then
echo "File is not removed."
else
echo "File is removed."
fi
else
echo "File does not exist."
fi
According to the output, the “t.txt” filename is located in the current location and the file is removed after the confirmation.

Conclusion
Different types of file operations in Bash are explained in this tutorial. The scripts of this tutorial will help the Bash user to know the various file-related tasks such as creating the files, appending the files, counting the file size, searching the content, replacing the content, deleting the files, etc.