This guide will explain the process of splitting code in the LangChain framework.
How to Split Code Using LangChain?
LangChain framework offers libraries to split code written in different languages like NodeJS, HTML, and many more. The model can split the code making small chunks of it to understand the code better and then generate responses for the queries on the code. To split the code into small chunks and train the model on the data, simply go through the following illustration:
Pre-requisite: Setup Modules
Firstly, start the procedure by installing LangChain packages so we can import libraries that can be used to split the code:
Now, import libraries like RecursiveCharacterTextSplitter and Language from LangChain to use them in the process:
RecursiveCharacterTextSplitter,
Language,
)
Before starting to split the code, let’s check the languages supported by the Language library so we can use their code and split it:
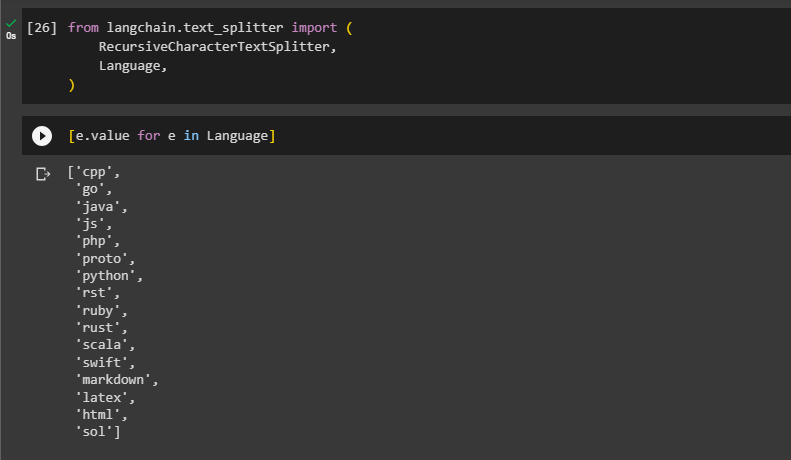
The above screenshot displays the list of languages supported by the library and we can split their code using LangChain.
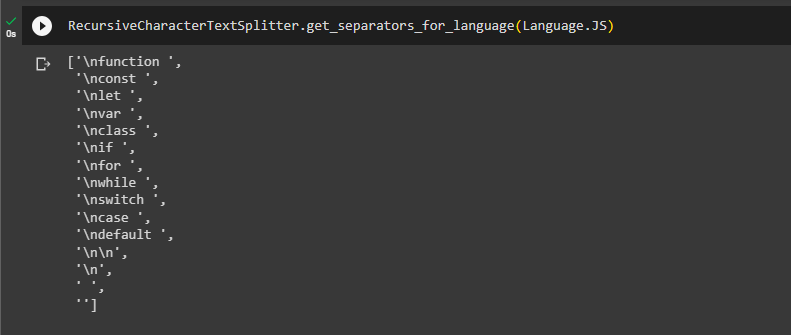
The user can get the splitter symbol for each language using the following code and it will generate all the splitter for that specific language:
The following screenshot displays the symbols that can be used to split the JS code:
Method 1: Using JS Code
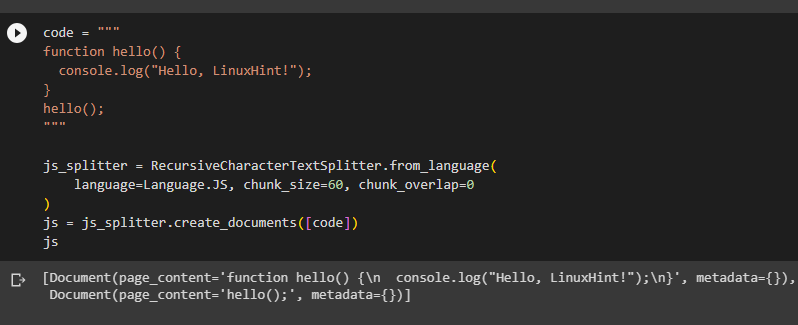
Write a JS code like a hello() function prints a line on calling it and store it in the code variable to use it for splitting the code:
function hello() {
console.log("Hello, LinuxHint!");
}
hello();
"""
js_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.JS, chunk_size=60, chunk_overlap=0
)
js = js_splitter.create_documents([code])
js
The above code has been split into 2 chunks and both of the parts have been displayed on the screen:
Method 2: Using Markdown Code
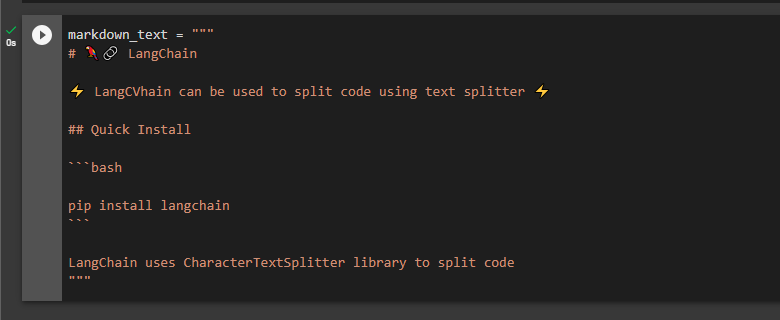
The next code we are using is written in the Markdown language, which is a markup language to create websites, technical documents, etc.:
# 🦜️🔗 LangChain
⚡ LangCVhain can be used to split code using text splitter ⚡
## Quick Install
```bash
pip install langchain
```
LangChain uses CharacterTextSplitter library to split code
"""
The above is the code written in the Markdown language for building the LLM application by installing the LangChain framework and storing it in the “markdown_text” variable:
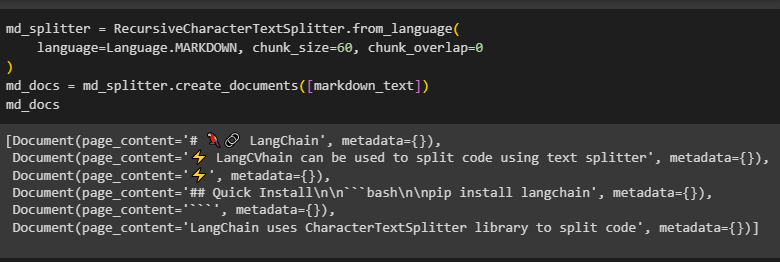
After that, simply apply the RecursiveCharacterTextSplitter() method and configure the chunks with other settings before printing it on the screen:
language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
md_docs
The code has been split into chunks of 60 characters and multiple pages are created as displayed in the following screenshot:
Method 3: Using Latex Code:
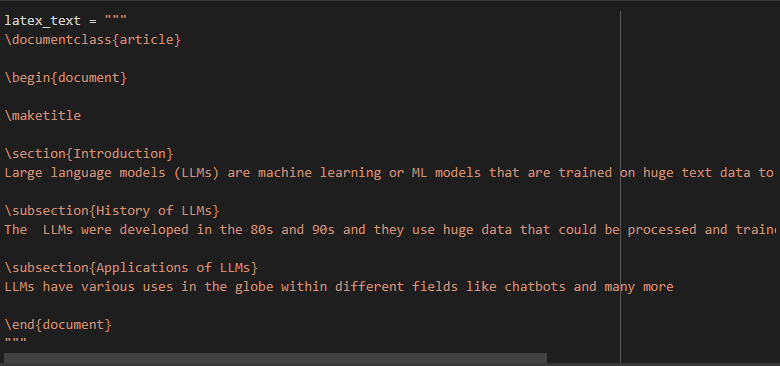
Latex is another markup language that specializes in the formatting of documents, rendering, typesetting, and many more:
\documentclass{article}
\begin{document}
\maketitle
\section{Introduction}
Large language models (LLMs) are machine learning or ML models that are trained on huge text data to generate text in natural language
\subsection{History of LLMs}
The LLMs were developed in the 80s and 90s and they use huge data that could be processed and trained the model to become interactive
\subsection{Applications of LLMs}
LLMs have various uses in the globe within different fields like chatbots and many more
\end{document}
"""
The above code creates a document class and initializes it with multiple sections like paragraphs to design a document. The document contains an introduction section about the Large Language Model and two subsections containing its history and applications before ending the file:
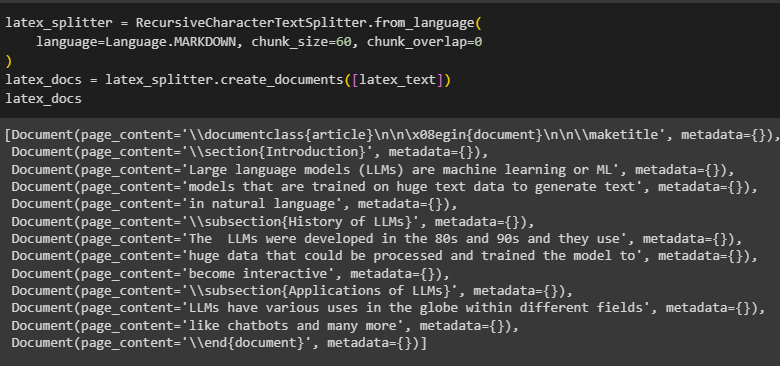
Simply define the text splitter method with its parameters to create small chunks of the code and then print them on the screen:
language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
latex_docs = latex_splitter.create_documents([latex_text])
latex_docs
The following screenshot displays multiple chunks of the complete code:
Method 4: Using HTML Code
HTML or HyperText Markup Language is used to build websites and display documents on these websites is another language that can be split using LangChain:
<!DOCTYPE html>
<html>
<head>
<title>🦜️🔗 LangChain</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: darkblue;
}
</style>
</head>
<body>
<div>
<h1>🦜️🔗 LangChain</h1>
<p>⚡ LangChain can be used to split the code ⚡</p>
</div>
<div>
LangChain uses CharacterTextSplitter library to split code in small chunks
</div>
</body>
</html>
"""
The above code creates a web page containing LangChain in dark blue color as its title followed by a heading and a paragraph line:
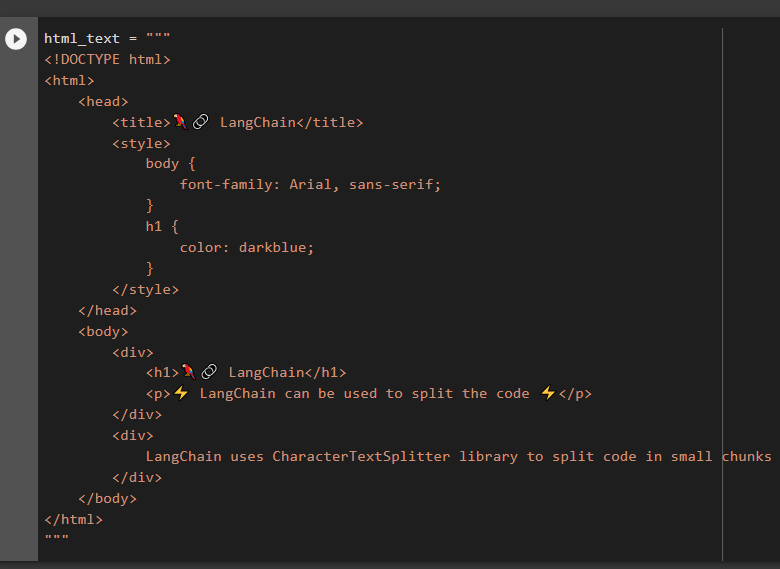
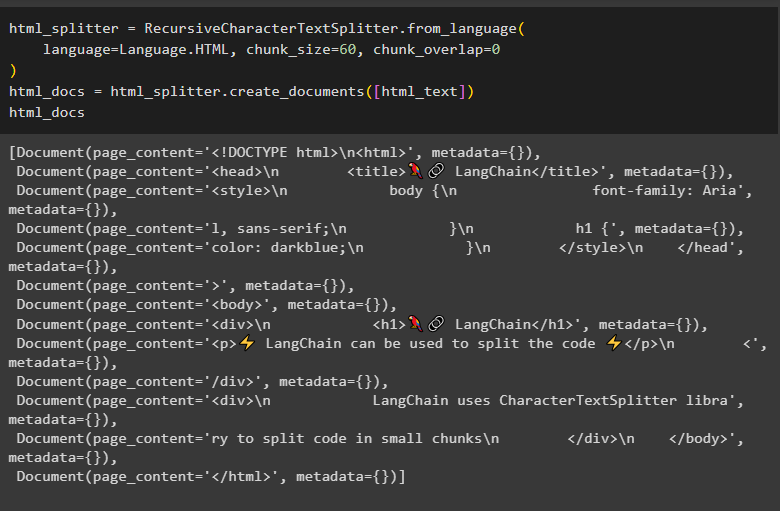
Now, simply split the HTML code in chunks of 60 characters and print the documents on the screen:
language=Language.HTML, chunk_size=60, chunk_overlap=0
)
html_docs = html_splitter.create_documents([html_text])
html_docs
Method 5: Using Solidity Code
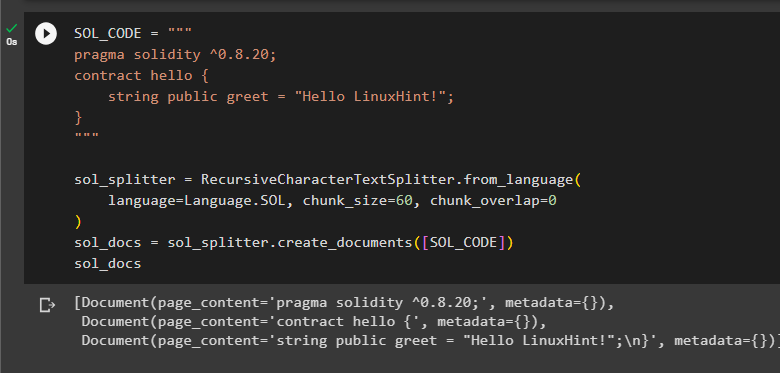
Solidity is a high-level language based on the object-oriented that is mostly used for building smart contracts:
pragma solidity ^0.8.20;
contract hello {
string public greet = "Hello LinuxHint!";
}
"""
sol_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.SOL, chunk_size=60, chunk_overlap=0
)
sol_docs = sol_splitter.create_documents([SOL_CODE])
sol_docs
The above code simply splits the solidity code into small chunks and display on the screen as displayed on the screenshot below:
Here is the guide that contains the process of splitting the Python code and now, that’s it about splitting code using the LangChain framework.
Conclusion
Code split is important for building Large Language Models as the user can ask the model to write code or understand code. It is required for the model to understand the code and it can be done by splitting code at the training stage using the LangChain libraries. After that, use multiple codes and split them by applying the RecursiveCharacterTextSplitter() method with its parameter. This post has illustrated the process of splitting code using LangChain with the code of different languages like JS, HTML, etc.