LangChain is a framework to build large Language Models using Artificial Intelligence so that it can generate text and interact with humans. The asyncio is the library that can be used to call a model like LLM multiple times using the same command or query. It also provides a boost in the speed of the working of our LLM model to generate text efficiently.
This article demonstrates how to use the “asyncio” library in LangChain.
How to Use/Execute the “asyncio” Library in LangChain?
Async API can be used as support for LLMs so for using the asyncio library in LangChain, simply follow this guide:
Install Prerequisites
Install the LangChain module to start using the asyncio library in LangChain to concurrently call LLMs:
The OpenAI module is also required to build LLMs using the OpenAIEmbeddings:
After the installations, simply configure the OpenAI API key using the following code:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")

Using asyncio to Build LLM
The asyncio library can be used for supporting LLMs as the following code uses it in LangChain:
import asyncio
#Importing asyncio libraries from LangChain to use it
from langchain.llms import OpenAI
#define the function to get the timestamp of serial generation
def generate_serially():
llm = OpenAI(temperature=0.9)
for _ in range(5):
resp = llm.generate(["What are you doing?"])
print(resp.generations[0][0].text)
#define the function to get the timestamp of synchronous generation
async def async_generate(llm):
resp = await llm.agenerate(["What are you doing?"])
print(resp.generations[0][0].text)
#define the function to get the timestamp of generate data concurrently
async def generate_concurrently():
llm = OpenAI(temperature=0.9)
tasks = [async_generate(llm) for _ in range(10)]
await asyncio.gather(*tasks)
#configure the resultant output using the asyncio to get concurrent output
s = time.perf_counter()
await generate_concurrently()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m")
#configure the timestamp for resultant output to get serial output
s = time.perf_counter()
generate_serially()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m")
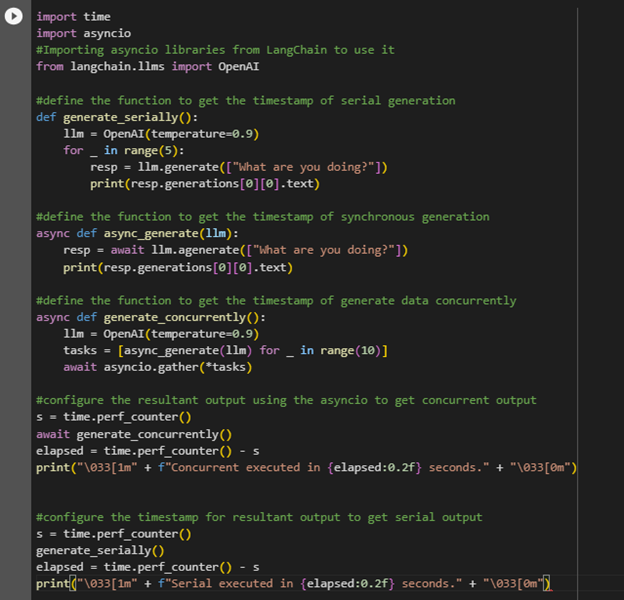
The above code uses the asyncio library to measure the time for generating texts using two distinct functions such as generate_serially() and generate_concurrently():
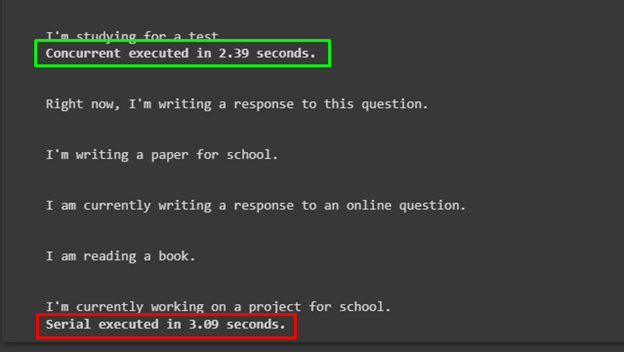
Output
The following screenshot displays that the time complexity for both the functions and the time complexity of concurrent text generation is better than the serial text generation:
That’s all about using the “asyncio” library to build LLMs in LangChain.
Conclusion
To use the asyncio library in LangChain, simply Install LangChain and OpenAI modules to get started with the process. The Async API can be helpful while building an LLM model for creating chatbots to learn from previous conversations. This guide has explained the process of using the asyncio library to support the LLMs using the LangChain framework.