
Keel (Knowledge Extraction based on Evolutionary Learning) is a Java-based software tool that specializes in the implementation of evolutionary algorithms. Since it is an open source, it provides a wide variety of knowledge discovery algorithms that can be used in experiments that power the data mining and analysis community. It provides a simple and easy-to-use graphical user interface that significantly decreases the overall complexity of this tool. Most similar tools on the market require the users to interact with them by writing the code whereas Keel removes this requirement by providing an intuitive GUI that can be used by beginners and experts alike.
Keel provides a wide variety of different computational intelligence-based algorithms including classification, regression, feature extraction, pattern analysis, clustering, and more. With mainstream models baked right into the application itself, Keel is a very useful tool when it comes to performing exploratory data analyses on raw data sets. Its simple drag and drop interface paired with the ease of functionality utilization allows for quick and efficient data mining experimentation for both educational and research purposes. Tools like Keel are increasing in popularity because of their simplistic approach to otherwise complex algorithmic practices.
Installation
There are two main ways in which we can install Keel on any Linux machine. The first one involves going to the Keel webpage and downloading the software from there. The second one, which we will follow in this installation guide, requires us to download Keel using the wget download tool available for Linux users.
1. We start by getting wget on our Linux machine.
Run the following command to download the wget using the apt package manager:
You will see a similar terminal output:
2. Now that we have the wget tool installed on our Linux machine, we use it to download the Keel tool.
This is the link that we pass to wget.
Run the following command in your terminal:
You should see a similar output on your terminal:
Once Keel is finished downloading, we can continue with the remainder of the installation.
3. We now extract the compressed file that we downloaded in the previous step using the Linux Unzip tool.
Run the following command:
You should see a similar output in the terminal:
4. Navigate into the Keel folder by running the following command:
5. Run the following command to start with the installation:
With this, Keel should be available for you to use on your Linux machine.
User Guide
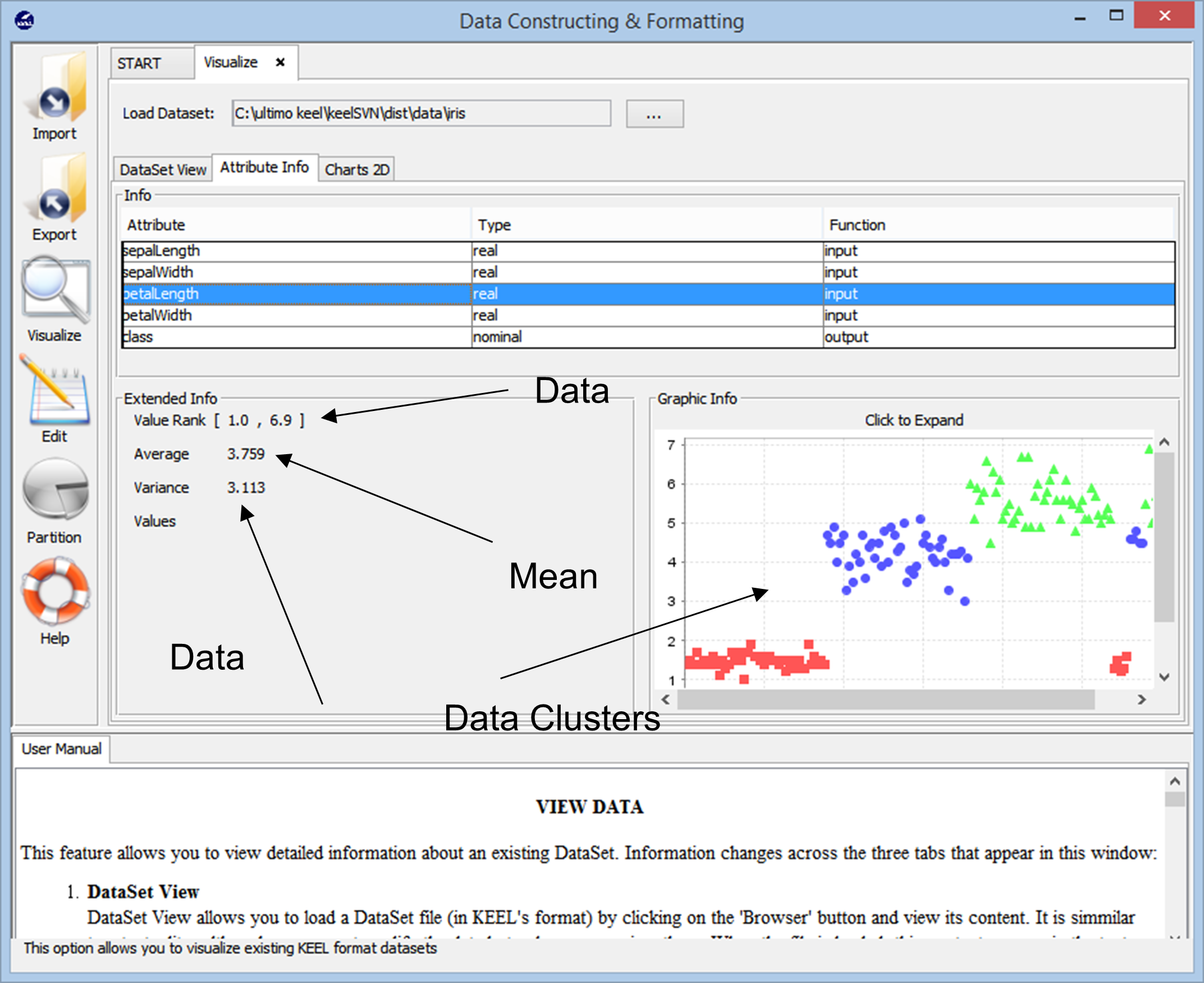
Interacting with the Keel application is really easy and simple. Let us start by importing the Iris data set into our workspace.
As we import the data, the tool shows us the overall clustering of the data point in the data set. It also shows us the different classes that are present in the data set along with the basic information like the numerical ranges that these data points span and the overall variance and mean values it present. This information allows the users to better understand how to proceed with the data preparation for any kind of data analysis task.
Proceeding further into the experimentation, we come across the different techniques that can be used to create our experiment on any data set. The different learning algorithms that can be used on our data can be seen in the following image. Depending on the nature of the data set and the requirements of the experiment, different algorithms can be experimented with.
For example, if you are working with unlabeled data and have to find similarities between the different data points in your data set, using a clustering algorithm from the various different options available can help you better understand the data points. This eventually helps you label and classify the data points so that the experiment can be built upon using more comprehensive supervised learning algorithms.
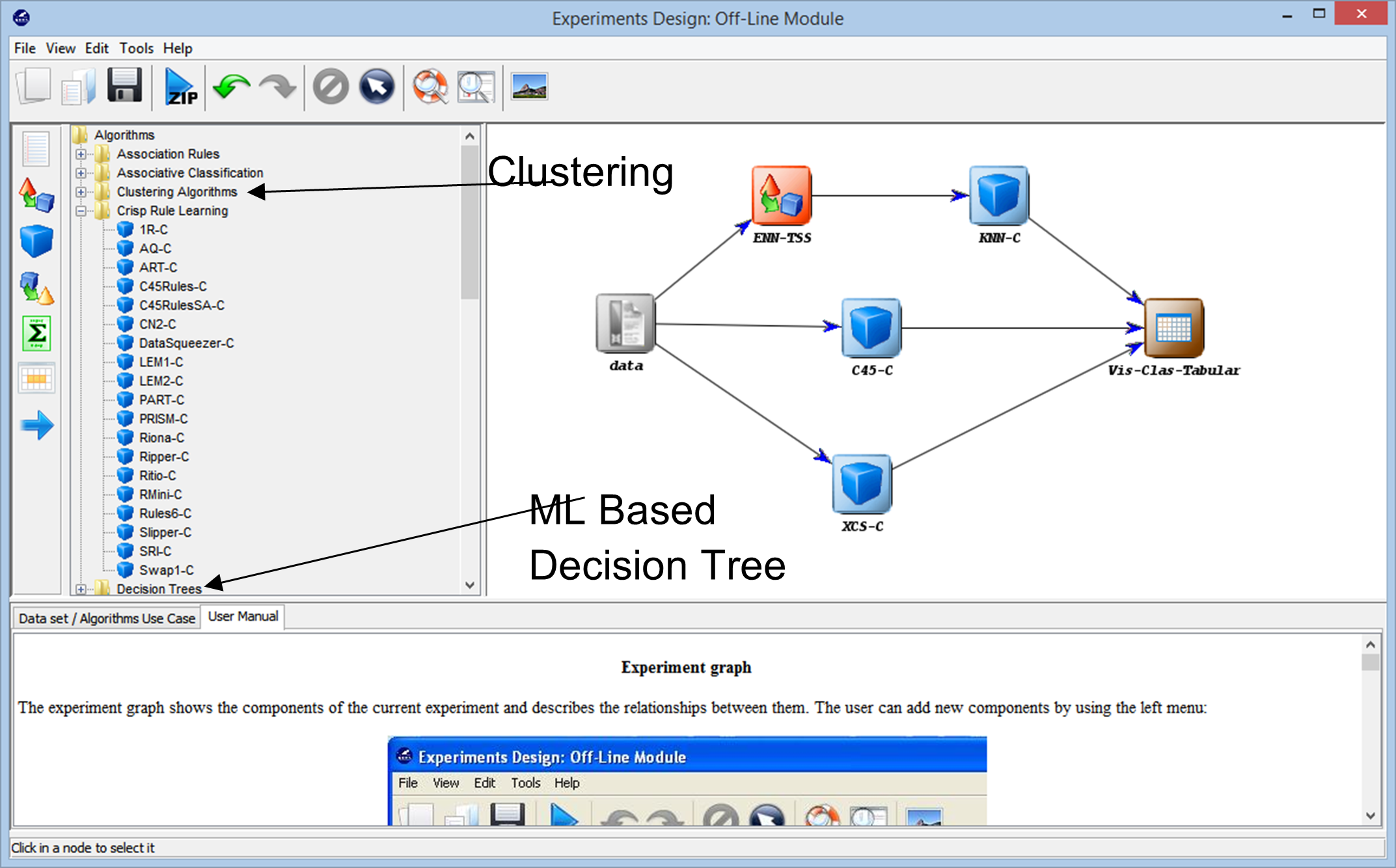
Conclusion
The Keel platform for data analytics is a good resource for both research and educational purposes. It’s easy-to-use graphical user interface helps the users to better understand the requirements of the data along with providing logical references to helpful techniques and algorithms that further aid the users in their workflows. Having a wide range of different algorithms that fall under the different categories and algorithmic techniques allow the users to experiment with numerous logical directions and compare these results so that the most optimum solution to any problem can be reached.
Keel’s code free drag and drop approach to data mining helps even the beginners to effortlessly work with comprehensive computational intelligence models. This provides insights into complex data sets and resultantly derives useful inferences that help solve the real world problems.