
Mahout is an open-source project by the Apache Software Foundation. It is used for the creation of machine learning algorithms and statistical or mathematical analyses. Mahout is able to take on fairly large data mining and machine learning tasks because of its distributed computing approach to such problems. Using Hadoop in the background, Mahout is able to divide the large data mining tasks into smaller subtasks which are then scheduled to run on different instances in a parallel fashion. This enables the user to accomplish a complex task relatively quickly by dividing it into smaller tasks and running them all together on different instances of the application using the cloud infrastructure.
Mahout provides its users with a range of different functionalities. These include techniques related to machine learning and data analytics, some of which are recommendation models, classification techniques, and clustering models. Since it is built on top of Hadoop, it enables the users to make use of Hadoop’s distributed cloud computing. Working seamlessly alongside Hadoop, Mahout is able to accomplish large data mining and analytics tasks really quickly, making it one of the best solutions to large data mining problems.
Installation
To use Mahout, you first need the Java (JDK) version 1.7, Maven version 3.0 or higher, and Subversion. Without these three dependencies, Apache Mahout will not work on your Linux machine.
Java JDK Installation
1. Go to the Java downloads page by clicking on this link.
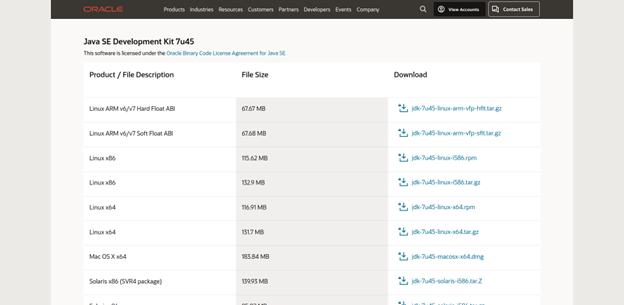
2. Select the Linux x64: jdk-7u45-linux-x64.tar.gz, accept the licensing terms, and download the file.
3. Go to the directory where you downloaded the file and open the terminal here.
Run the following command:
This copies the extracted folder into /usr/local/lib/.
4. Move into the /usr/local/lib/ folder by running the following command:
5. Run the following command in the terminal to extract the contents of the compressed folder:
6. Remove the compressed file which we just extracted:
7. Move into your Home/Username/ by running the following command:
8. Add the Java Home to the path by carrying out the following steps:
Run the following command:
Add the following two lines at the end of the profile that we just opened.
export PATH="$JAVA_HOME/bin:$PATH"
Maven Installation
1. With a Java JDK now installed, we now install Maven which is the second requirement to run the Mahout.
Run the following command in the terminal:
You should see an output which is similar to the following illustration:
To check whether Maven has been successfully installed on your machine, run the following command in the terminal:
Subversion Installation
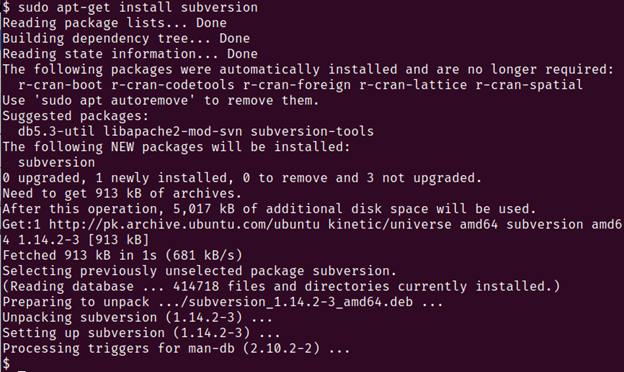
1. With Maven now successfully installed, we now install Subversion. Subversion is a free to use software revision control system. It enables the users to keep track of different versions of source code on their machines.
Run the following command:
You should see a similar output in your terminal:
Run the following command to check whether Subversion has been successfully installed:
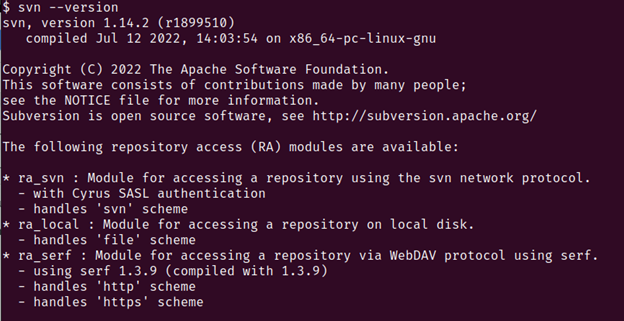
2. With Subversion now installed, we have successfully installed all of the dependencies for Mahout.
We will now proceed to download and install Mahout.
First, move into the directory that you want to install Mahout in.

Run the following command:
You should see a similar terminal output:
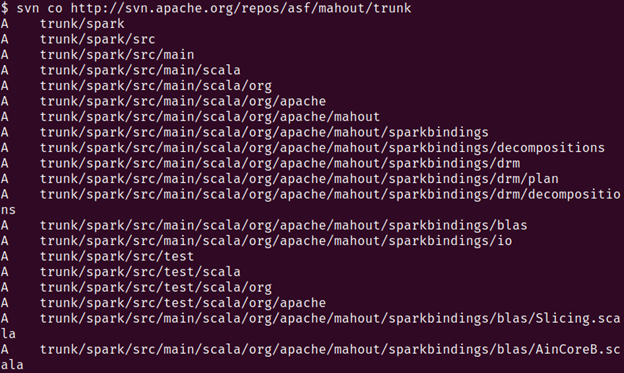
We now move into the trunk directory:
Now, run the following command:
You should now have Apache Mahout ready to use on your Linux machine.
User Guide
Mahout uses a programming interface to unlock the potential of Mahout distributed computing. The language that is used to interact with this framework is Java.
Mahout is a comprehensive solution to complex machine learning and data mining tasks. Since it does not provide an interactive user interface, users must know the use of the Java language to unleash the full potential of this framework.
This means that Mahout cannot be used by people who are not fluent in Java. This does not however mean that one does not have to try. Learning a new programming language is something that is not complex today. With resources readily available, one can easily learn Java and interact with the Mahout framework to create algorithms that can be used with large data sets to find the solutions and patterns to problems in a distributed environment.
Conclusion
There are many data mining and machine learning frameworks that are available on the market today. Mahout by Apache is one of these frameworks. Mahout is famous for allowing the use of a distributed environment using Hadoop over the cloud to divide the complex data mining tasks into smaller subtasks that can be run on multiple instances of the application. This results in the larger task being completed in a shorter span of time while also scaling down the overall compute power that is used to smaller units.
Mahout is used by writing the code in Java which is a language that has made its name by surviving the tests of time. This makes Java a very useful skill to have. Learning Java to use this functionality offered by Apache is something that most data scientists do at some point in their careers. While most data mining professionals will never need to use the distributed cloud computing in the field of data science, it does however exist for the small amount of tasks that require a more scalable distributed solution.