Actual Syntax
It takes an SQL Expression and performs some operations within the expression.
Let’s discuss it one by one. Before that, we have to create a PySpark DataFrame for demonstration.”
Example
We are going to create a dataframe with 5 rows and 6 columns and display it using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display dataframe
df.show()
Output
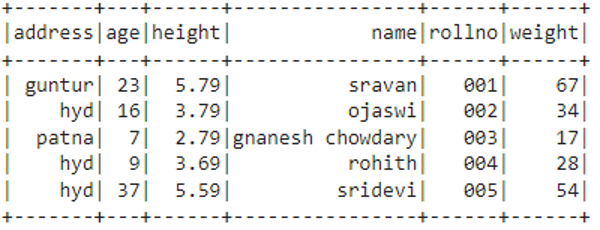
Scenario 1: Concatenating One or More Columns
In this scenario, we will concatenate one or more columns in the PySpark DataFrame using expr().
It uses the withColumn() method to create a new column name for the concatenate columns.
Syntax
Parameters
It takes two parameters.
- First is the column name used as the column name for the concatenated columns
- Expression is created using expr() to concatenate columns.
Here the expression is :
Here, column refers to the column names to be concatenated with a separator in between them. It can be any character, like special characters.
Example
In this example, we are concatenating three columns – roll no name and address separated by “-“ and the column name for these concatenated columns is – “rollno with name and address.”
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#concate rollno,name and address columns uaing expr()
df.withColumn("rollno with name and address", expr("rollno|| '-'|| name || '-' || address")).show()
Output
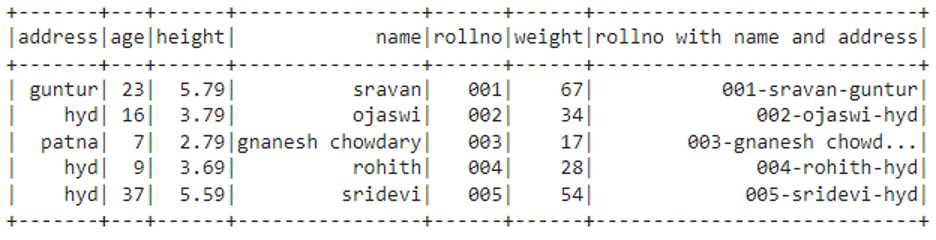
We can see that rollno, name, and address columns are concatenated with the “-“ separator.
Scenario 2: Add a New Column Based on Conditions
Here, we will use expr() to specify the conditions inside it and, along withColumn(), to assign the values from the conditions returned in a new column.
We can specify the conditions using CASE WHEN
Structure
THEN
CASE WHEN
THEN
…..
…..
ELSE
END
Inside, when we have to provide the condition and inside, THEN we have to perform an action.
If the condition inside is True, THEN the block is executed. If it fails, it goes to the ELSE block and END.
This conditional statement is provided inside expr() as an SQL Expression.
Syntax
Where,
- column is the new column that is created, and values are assigned based on the conditions in this column
- expr() takes CASE WHEN conditional logic
Example
In this example, we are creating a new column – “upgraded Height,” and assigning values to it based on the following conditions applied to the height column.
If the height is greater than 5 – assign 10 in the upgraded Height column across it.
If the height is less than 5 – assign 5 in the upgraded Height column across it.
Otherwise, upgrade the Height column to 7 across the rows.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#In height column
#if height is greater than 5 - assign 10 in upgraded Height column across it
#if height is less than 5 - assign 5 in upgraded Height column across it
#otherwise upgraded Height column as 7 across the rows
df.withColumn("upgraded Height", expr("CASE WHEN height >5 THEN 10 " +"WHEN height <5 THEN 5 ELSE 7 END")).show()
Output
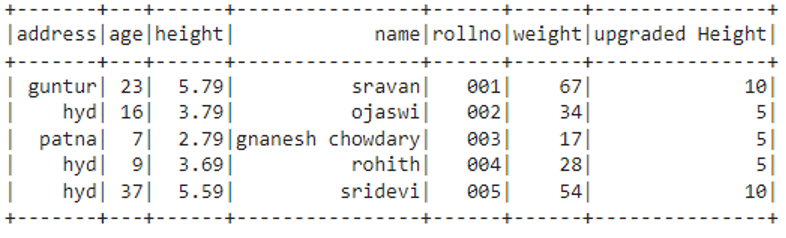
We can see that values are allocated in the “upgraded Height” column based on the conditions.
Scenario 3: Perform Arithmetic Operations
It is possible to perform arithmetic operations like addition, subtraction, multiplication, and division with existing columns using expr().
Here expr() can be used with a select clause to display the updated columns.
Syntax
The expression is used to perform arithmetic operations that can be:
“column arithmetic_operator value as new_column”
Here, the column is the column name in which we can perform arithmetic operations; value is the number added to each row in the column, and new_column is the column name that stores the result.
Example
In this example, we will perform two arithmetic operations – addition and subtraction on the age column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#add 10 to age column
df.select(df.age,expr("age + 10 as age_after_10")).show()
#subtract 10 from age column
df.select(df.age,expr("age - 10 as age_before_10")).show()
Output
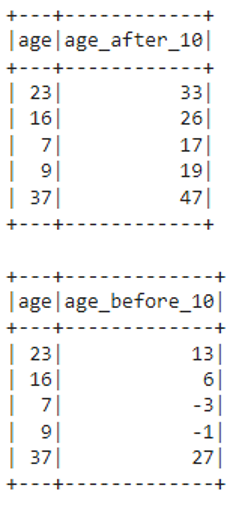
In the addition operation, we are adding 10 to the age column and store in the “age_after_10” column.
In the subtraction operation, we subtract 10 from the age column and store it in the “age_before_10” column.
Conclusion
In this PySpark tutorial, we saw how to use expr() in three different scenarios. It can be used for conditional expressions, It can be used to perform arithmetic operations, and it can be used to concatenate multiple columns.