In a production environment, we often come across a point where we need to provide our services and applications with the ability to access our S3 buckets. We have to keep these permissions very specific for each service or user. Hence, each one of them only gets those permissions that are necessary for them; otherwise, we may get privacy and security issues. Now, this type of access permission cannot be managed by the IAM policies as they act in a similar way for all our users and customer applications. To resolve this problem, AWS has come up with another method to create access points for each service so that each user can be linked to a single S3 bucket using different access points. Each access point can be managed separately using its own policy, which works with the original bucket’s policy. You can create one thousand access points in each AWS region by default, but this limit can be increased by requesting AWS. These access points are also known as network access points.
This article will see how to create and manage network access points for our S3 buckets in AWS.
Creating S3 Access Point Using Management Console
First, you need to login into your AWS account in your browser using a username and password. As we will manage access points for S3 buckets, the user must have the permissions to manage and access the S3 service.
In the management console, search for S3 in the top search bar and select S3 service from the results that appear below.
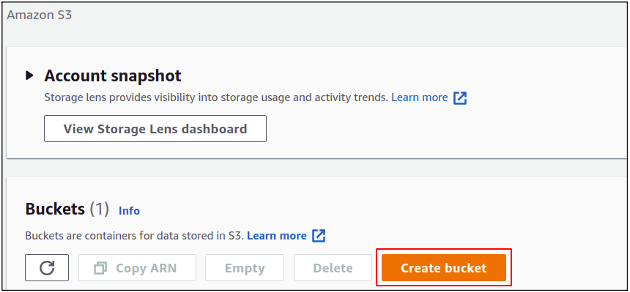
Here we will create a new S3 bucket in our account, so simply click on create the bucket.
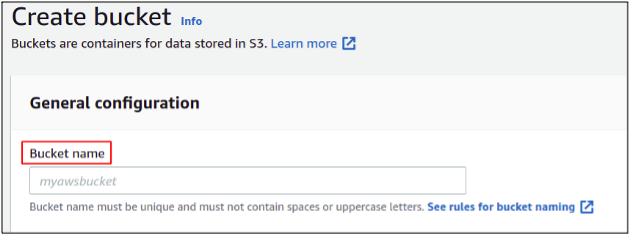
Now in the bucket, create a section; you need to provide a bucket name. The bucket name must be unique in the whole AWS database as S3 buckets are virtually hosted websites, so the bucket naming rules are just like our DNS roles.
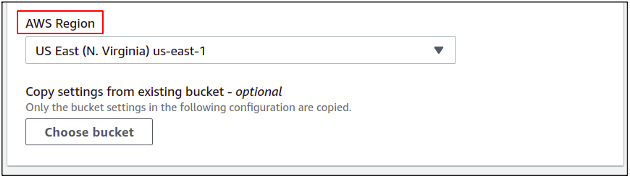
Then you need to select the AWS region where you want to create a new bucket. AWS regions are located worldwide in many different countries, and each region may have two or more physically isolated data centers, which we call availability zones. As an AWS privacy policy, users’ data never leave a region without the owner’s consent. Regardless of the placement of our S3 bucket, the data inside it can be accessed using any region globally.
Next, you will find other settings in this section like versioning, encryption and public access etc., but you can simply leave them as default and scroll down to click on the create bucket in the bottom right corner to finish the bucket creation process.
So finally, we have created a new S3 bucket in our AWS account.
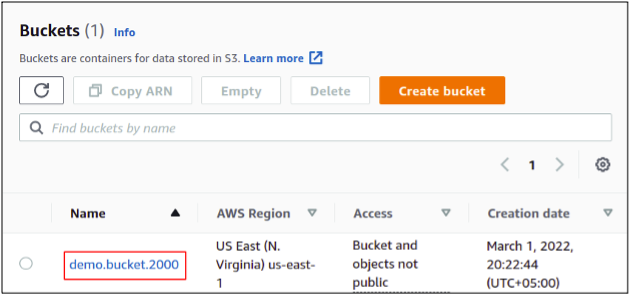
Now our bucket is ready, we can manage the access points. Simply select the bucket for which you want to create an access point and click on the access points from the top menu bar.
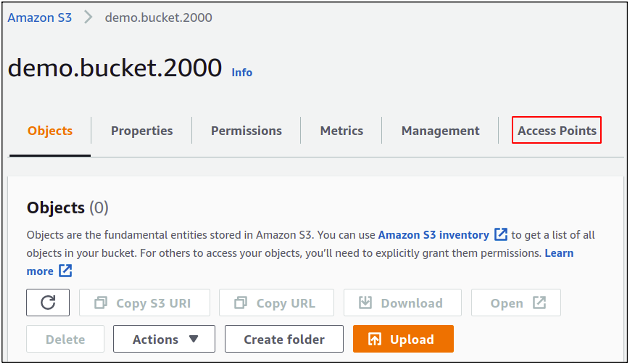
Click on the create an access point to start configuring it for your bucket.
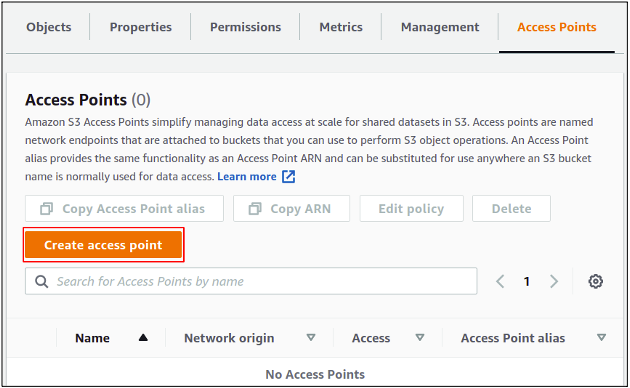
In this section, first, you need to define a name for your access point.
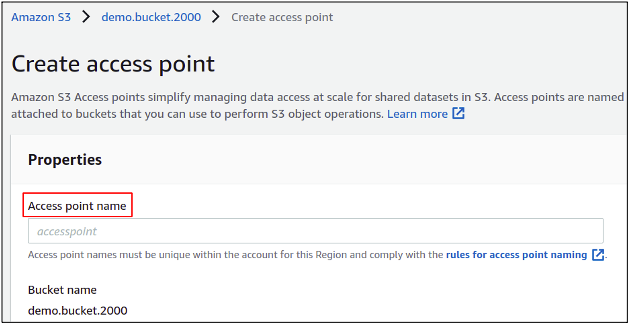
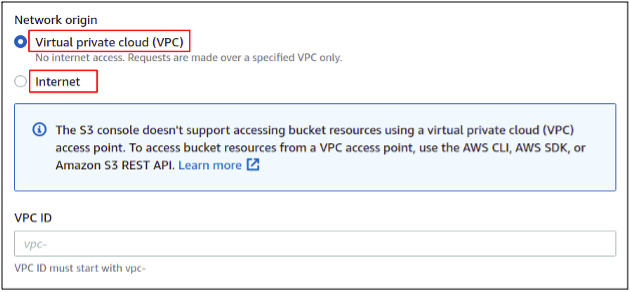
Next, you need to choose whether you want your access point to be only accessible inside your virtual private network (VPC), or you want to make it publicly accessible over the internet. If you want your access points to be available over the internet, make sure to apply the public access settings and policies correctly, as this may trouble your data security and privacy.
Lastly, each access point can be managed using a different policy we attached to it. Both the bucket policy and access point policy will act in a combined manner to decide whether a user can get access to the data using the access point. Here we are simply going with the default policy.

To complete the creation process, click on create an access point in the button right corner.
After creation, you can easily view and manage these access points under the access point section
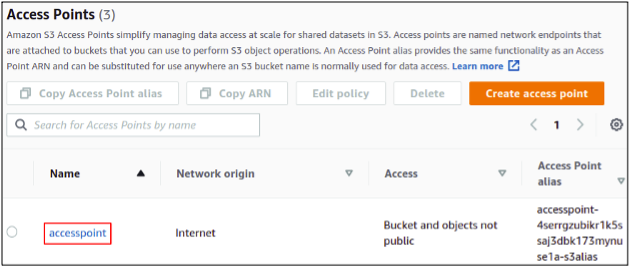
So we have successfully created and configured an S3 access point using the management console.
Configure S3 Access Point Using AWS CLI
The AWS management console provides an easy way to manage AWS services and resources using a nice graphical user interface, but from an industrial point of view, this has many limitations; that is why most professionals prefer using the AWS command-line interface to deal with AWS accounts. You can set AWS CLI on any desktop environment, either Mac, Windows or Linux. So let’s see how we can create an S3 access point using the CLI
First, we need to create an S3 bucket in our AWS account. For this, we need to run the following command.
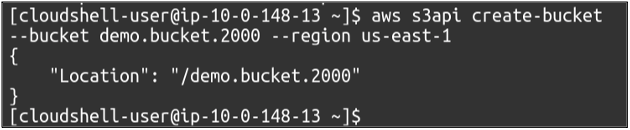
You can also confirm the bucket creation by listing the available buckets in your AWS account. Simply use the following command.
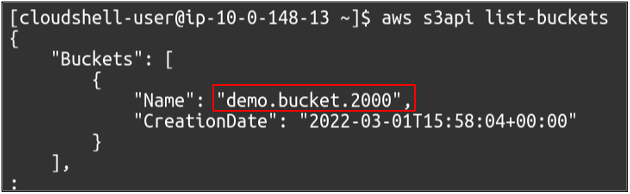
Once the bucket creation is completed, you can now configure the S3 access point. For this, you need to run the following command in the terminal.
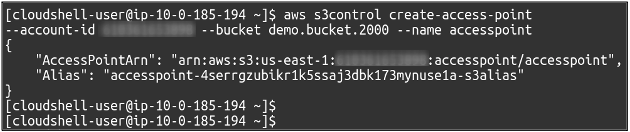
You can also observe all access points configured in your account using the following command.
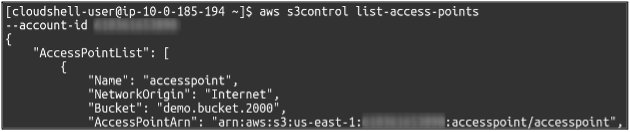
So we have successfully created our S3 network access point using the AWS command-line interface. You can also manage the network access control and access point policy using the CLI.
Conclusion
S3 access points are very helpful if you want to provide limited access to each service and user application. Using the bucket policy, all the users get to have the same permissions but use access points; if one application gets the GetObject permission, the other may get PutObject rights. So they can ensure your bucket privacy and security while ensuring that each consumer gets the right set of permissions he needs to perform his job successfully.