In Python, PySpark is a Spark module used to provide a similar kind of processing like spark using DataFrame.
We can traverse the PySpark DataFrame through rows and columns using:
Before moving to the these, we will create PySpark DataFrame.
Example:
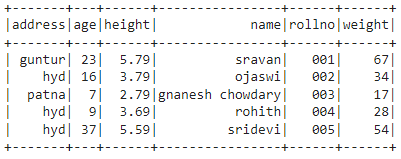
Here, we are going to create PySpark dataframe with 5 rows and 6 columns.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:
collect()
This method is used to iterate the columns in the given PySpark DataFrame. It can be used with for loop and takes column names through the iterator to iterate columns. Finally, it will display the rows according to the specified columns.
Syntax:
print(row_iterator[‘column’],…….)
Where,
- dataframe is the input PySpark DataFrame.
- column is the column name in the PySpark DataFrame.
- row_iterator is the iterator variable used to iterate row values in the specified column.
Example 1:
In this example, we are iterating rows from the rollno, height and address columns from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# iterate over rollno,height and address columns
for row_iterator in df.collect():
print(row_iterator['rollno'],row_iterator['height'],row_iterator['address'])
Output:
002 3.79 hyd
003 2.79 patna
004 3.69 hyd
005 5.59 hyd
Example 2:
In this example, we are iterating rows from name column from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# iterate over name column
for row_iterator in df.collect():
print(row_iterator['name'])
Output:
ojaswi
gnanesh chowdary
rohith
sridevi
select()
This method is used to iterate the columns in the given PySpark DataFrame. It can be used with collect() method and takes column. Finally, it will display the rows according to the specified columns.
Syntax:
Where,
- dataframe is the input PySpark DataFrame.
- column is the column name in the PySpark DataFrame.
Example 1:
In this example, we are iterating rows from the rollno and name column from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#iterate rollno and name columns
df.select("rollno", "name").collect()
Output:
Row(rollno='002', name='ojaswi'),
Row(rollno='003', name='gnanesh chowdary'),
Row(rollno='004', name='rohith'),
Row(rollno='005', name='sridevi')]
Example 2:
In this example, we are iterating rows from the rollno and weight column from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#iterate rollno and weight columns
df.select("rollno", "weight").collect()
Output:
Row(rollno='002', weight=34),
Row(rollno='003', weight=17),
Row(rollno='004', weight=28),
Row(rollno='005', weight=54)]
iterrows()
This method is used to iterate the columns in the given PySpark DataFrame. It can be used with for loop and takes column names through the row iterator and index to iterate columns. Finally, it will display the rows according to the specified indices. Before that, we have to convert into Pandas using toPandas() method.
Syntax:
print(row_iterator[index_value], ………)
Where,
- dataframe is the input PySpark DataFrame.
- index_value is the column index position in the PySpark DataFrame.
- row_iterator is the iterator variable used to iterate row values in the specified column.
Example 1:
In this example, we are iterating rows from the address and height columns from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#iterate address and height columns
for index, row_iterator in df.toPandas().iterrows():
print(row_iterator[0], row_iterator[1])
Output:
hyd 16
patna 7
hyd 9
hyd 37
Example 2:
In this example, we are iterating rows from the address and name columns from the above PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17, 'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#iterate address and name columns
for index, row_iterator in df.toPandas().iterrows():
print(row_iterator[0], row_iterator[3])
Output:
hyd ojaswi
patna gnanesh chowdary
hyd rohith
hyd sridevi
Conclusion
In this tutorial, we discussed how to iterate over rows and columns in the PySpark DataFrame. We discussed three methods – select(), collect() and iterrows() with for loop. So, by using these methods we can specify the columns to be iterated through row iterator.