It will return the tree-like structure and get column name along with datetype
Syntax:
Before going to see this, we have to create a DataFrame with Schema. PySpark provides the StructType() and StructField() methods which are used to define the columns in the PySpark DataFrame.
Using these methods, we can define the column names and the data types of the particular columns.
Let’s discuss one by one
StructType()
This method is used to define the structure of the PySpark dataframe. It will accept a list of data types along with column names for the given dataframe. This is known as the schema of the dataframe. It stores a collection of fields
StructField()
This method is used inside the StructType() method of the PySpark dataframe. It will accept column names with the datatype.
Syntax:
StructField("column 1", datatype,True/False),
StructField("column 2", datatype,True/False),
………………………………………………,
StructField("column n", datatype,True/False)])
Where schema refers to the dataframe when it is created
Parameters:
1. StructType accepts a list of StructFields in a list separated by a comma
2. StructField() adds columns to the dataframe, which takes column names as the first parameter and the datatype of the particular columns as the second parameter.
We have to use the data types from the methods which are imported from the pyspark.sql.types module.
The data types supported are:
- StringType() – Used to store string values
- IntegerType() – Used to store Integer or Long Integer values
- FloatType() – Used to store Float values
- DoubleType() – Used to store Double values
3. Boolean values as the third parameter; if it is True, then the given data type will be used; otherwise, not when it is False.
We have to pass this schema to the DataFrame method along with data.
Syntax:
Example 1:
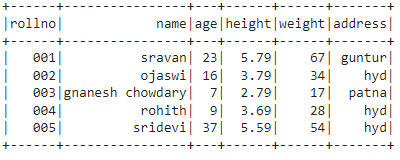
In this example, we created data within the list that contains 5 rows and 6 columns, and we are assigning columns names as rollno with the string data type, a name with the string data type, age with integer type, height with a float type, weight with integer and address with the string data type.
Finally, we are going to display the dataframe using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[['001','sravan',23,5.79,67,'guntur'],
['002','ojaswi',16,3.79,34,'hyd'],
['003','gnanesh chowdary',7,2.79,17,'patna'],
['004','rohith',9,3.69,28,'hyd'],
['005','sridevi',37,5.59,54,'hyd']]
#define the StructType and StructFields
#for the below column names
schema=StructType([
StructField("rollno",StringType(),True),
StructField("name",StringType(),True),
StructField("age",IntegerType(),True),
StructField("height", FloatType(), True),
StructField("weight", IntegerType(), True),
StructField("address", StringType(), True)
])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(students, schema=schema)
#display the dataframe
df.show()
Output:
Example 2:
Display the schema in tree format with printSchema() method
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[['001','sravan',23,5.79,67,'guntur'],
['002','ojaswi',16,3.79,34,'hyd'],
['003','gnanesh chowdary',7,2.79,17,'patna'],
['004','rohith',9,3.69,28,'hyd'],
['005','sridevi',37,5.59,54,'hyd']]
#define the StructType and StructFields
#for the below column names
schema=StructType([
StructField("rollno",StringType(),True),
StructField("name",StringType(),True),
StructField("age",IntegerType(),True),
StructField("height", FloatType(), True),
StructField("weight", IntegerType(), True),
StructField("address", StringType(), True)
])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(students, schema=schema)
# display the schema in tree format
df.printSchema()
Output:
