
Prerequisites
To apply pipe commands on Linux, you need to have a Linux environment in your system. This can be done by downloading a virtual box and configuring an Ubuntu file on it. Users must have privileges to access the applications required.
Syntax
Command 1 | command 2 | command 3 | ……
Sort the list using pipes
The pipe has much functionality used to filter, sort, and display the text in the list. One of the common examples is described here. Suppose we have a file named file1.txt having the names of the students. We have used the cat command to fetch the record of that file.
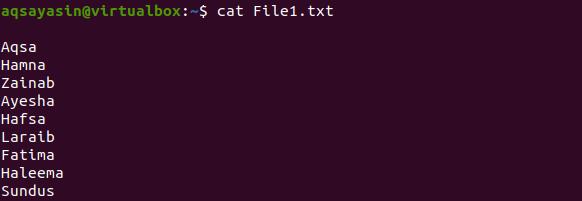
The data present in this file is unordered. So, to sort the data, we need to follow a piece of code here.
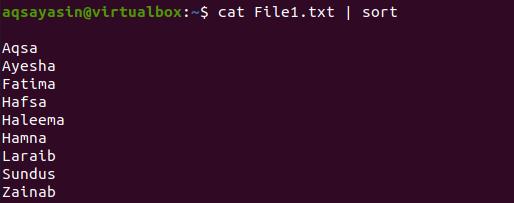
Through the respective output, you can see that students’ names are arranged alphabetically in a sequence from a to z.
Beside this. Suppose we want to get an output in sorted form plus removing redundancy. We will use the same command and a “uniq” keyword in addition to the default command. Let’s consider a file named file2.txt having the names of subjects in it. The same command is used for fetching data.
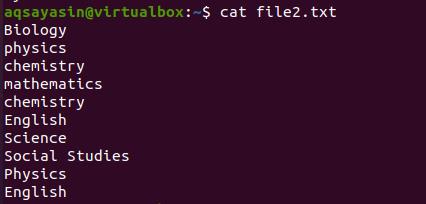
Now we will use the command to remove all the words that are duplicated in the file.
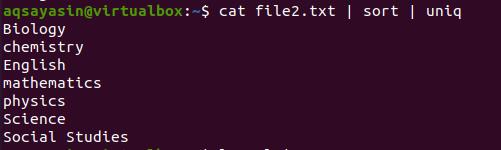
The output shows that the elements are organized and arranged alphabetically. At the same time, all the words that were duplicated are removed. The above command will only display the output, but we will use the below-cited command to save them.
The output will be saved in another file with the same extension.
Display file data of a corresponding range
It is very annoying when you want to get some data only from the start, but the command gives you all the matching items in your system. You can use the ‘head’ keyword. It helps to limit your output with concerning some range. i.e., in this example, we have declared the range up to 4. So the data will be from the first 4 lines of the file. Consider the same file file2.txt as we have taken an example above.
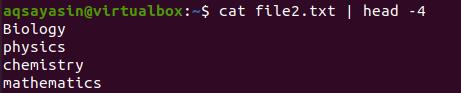
Similar to head, we can also use the tail option. This will limit the output to the last lines according to the range given.
Pipe and more command
By using more command, all the output is displayed at a time on the screen. The pipe act as a container and displays all the output data as an input of ls-l. Because the output is a long list of files.
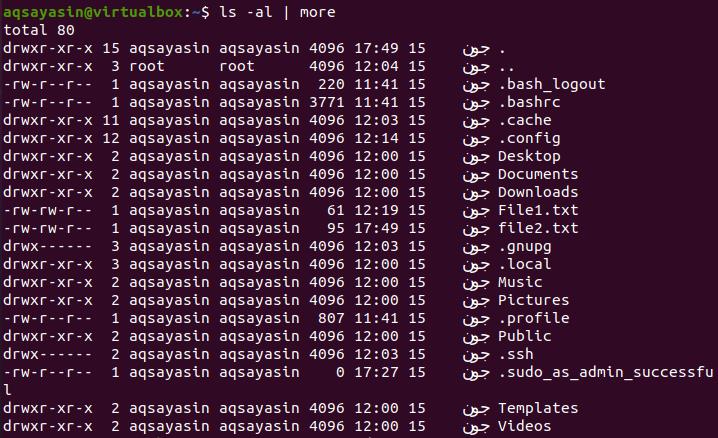
Ls is used to display all possible data of the respective command. It firstly displays the total number of data related to the corresponding query.
Count the number of files
It is a common need to know the number of files currently present. And it is not necessary to use the grep or cat command to fetch data of all the types. We can use pipe in this case either. The command used is written as:
![]()
Whereas wc is “word count” used to count the files present.
Process identification
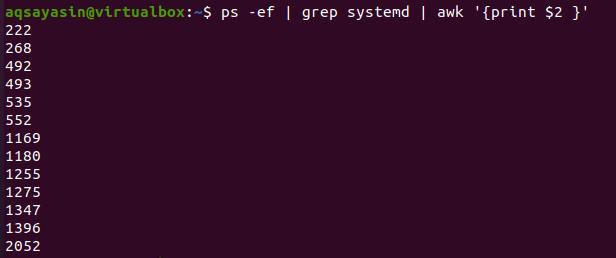
Many complicated tasks are also performed by using the pipe in our commands. The command we are discussing now is used to display the process ids of the systemd processes.
The awk command’s $2 displays the data of $2 that is the second column.
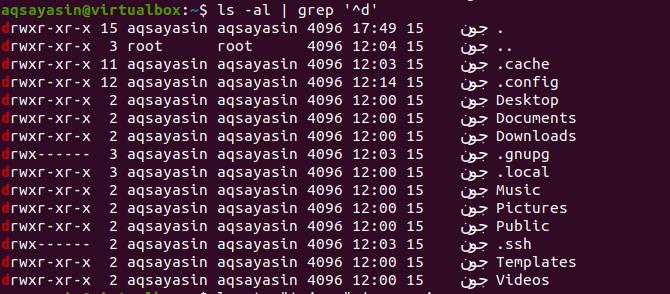
Get sub-directories using pipe
One of the pipeline commands we have used to get all the present subdirectories in the current directory is one of the pipe queries in the pipeline commands we have used. We have used the grep command here. Grep only functions to show the data starting from the ‘d’. The pipe will help in retrieving the respective data of all the directories. ‘^d’ is used here.
Get files using pipe
To get the files from the system of respective extensions, we can get this by using the pipe in our commands. The first example is finding the java files in the system. ‘locate’ and ‘grep’ help get the files of respective extensions.
![]()
‘*’ is used to fetch all the files in the system. Currently, we have a single file present in our system. The second example is to get the files with the extension of the text. The entire command is the same only the file extension is changed.

Use multiple pipes in a single command
In this example, unlike the earlier ones, we have used more than one pipe in a single command to elaborate its functionality. Consider a file named file3.txt.
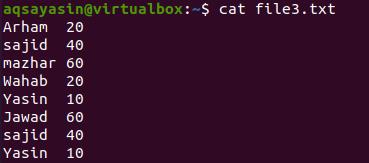
Now we want to get the record of the word that matched with the name we have provided in the command. Here cat command is used to fetch the data from a particular file. Grep is used to select that specific word from the file. ‘tee’ is used to save the result in another file. And wc is to count the resultant data. So the result is shown below.
![]()
The word is matched with the 2 contents. We can display the data from the new sample file to display the whole result, where the result is being stored.
Fetch particular data with pipes
In this example, we want to get the data from the file having ‘h’ in its content.

The result shows that the fetched data is according to the search by the ‘h’ command. Moving towards the following example. Here we want to fetch the items of the file having ‘s’ in it, but we have applied a condition of case sensitivity. Both upper and lower case alphabets will be fetched.
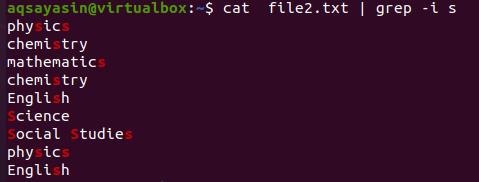
The result is shown in the image. Next, we will display the students’ names having alphabets ‘a’ and ‘t’ combined in the word. The result is in the below-cited image.
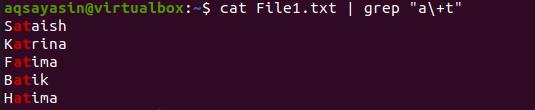
Conclusion
The article depicts the versatility of pipe in Linux commands. However, it is quite simple but works in a manner to resolve many complex queries. This command-line utility is easily implementable and compatible with UNIX and Linux operating systems.