
Syntax:
The following “grep” command is used to search a particular string or text in a file.
The following “grep” command is used to search a particular string or text in multiple files.
The following “grep” command is used to search multiple strings with space in a file.
The following “grep” command is used to search a string with a particular option in a file. Different options are used with the “grep” command for different purposes.
The following “grep” command is used to search a particular pattern in a file.
The following “grep” command is used to search a particular pattern with the option in a file.
The following “grep” command is used to search strings with alternation in a file.
The following “grep” command is used to search a particular pattern in the output of the “ps” command.
The “grep” command displays the matching lines of the file based on the searching string or pattern by default. The 30 different uses of the “grep” command are shown in this tutorial with simple examples.
Content:
- Search Matching String
- Search Non-Matched String Only
- Search String With Case Insensitive Match
- Search Whole Word Only
- Search Multiple Files in the Current Directory
- Search Recursively in a Directory
- Search Without Using Filename
- Add Line Number to the Output
- Use of Wildcard to Match a Single Character
- Use of Wildcard to Match Zero or More Times
- Use of Wildcard to Match One or More Times
- Use of Wildcard to Match the Exact Number of Times
- Print the Particular Number of Lines After the Matching Lines
- Print the Particular Number of Lines Before the Matching Lines
- Print the Particular Number of Lines After and Before the Matching Lines
- Match Specific Digits Using Third Brackets []
- Match a Pattern With Specific Characters Using Third Brackets []
- Match Alphabetic and Numeric Characters Using [:alnum:] Class
- Match Alphabetic Characters Using [:alpha:] Class
- Match Numeric Characters Using [:digit:] Class
- Match Lowercase Characters Using [:lower:] Class
- Match Printable Characters Using [:print:] Class
- Match Space Character Using [:space:] Class
- Match From the Beginning of the Line
- Match to End of the Line
- Match With Concatenation
- Match With Alternation
- Match With Back References
- Combine “grep” With the “ps” Command Using Pipe
- Combine “grep” With the “awk” Command to Print Specific Fields
Search Matching String:
The simplest use of the “grep” command is to search a particular string in a file. Create a simple text file named customers.txt with the following content to check different types of “grep” commands:
customers.txt
11 Md. Abir abir@gmail.com +8801813462458
23 Riya Chakroborti riya@gmail.com +8801937864534
45 Minhaz Ali ali@gmail.com +8801190761212
56 Maliha Chowdhury maliha@gmail.com +8801820001980
79 Maruf Sarkar maruf@gmail.com +8801670908966
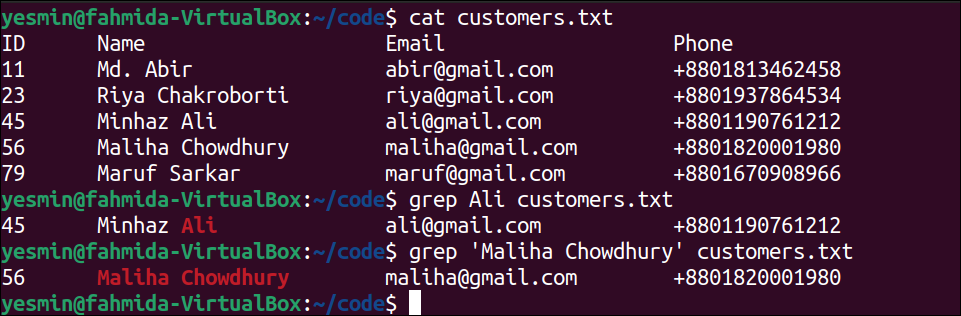
The following command will display the content of the customers.txt file:
The following “grep” command will search the string ‘Ali’ in the customers.txt file. If the searching string exists in the file, then the line containing the string will be printed:
The following “grep” command will search the text ‘Maliha Chowdhury’ in the customers.txt file. If the searching text exists in the file, then the line containing the text will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the string ‘Ali’ exists in line 4, and the text ‘Maliha Chowdhury’ exists in line 5 of the customers.txt file. So, the fourth line of the file has printed for the first “grep” command, and the fifth line of the file has printed for the second “grep” command.
Search Non-Matched String Only:
The -v option of the “grep” command is used to search non-matched strings from a file. In this example, the “grep” command with the -v option has been used to search non-matched string from the customers.txt file created in the first example.
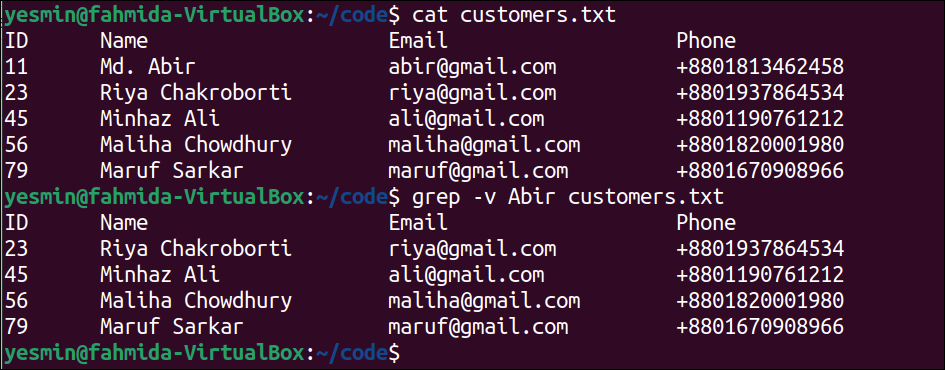
The following command will display the content of the customers.txt file:
The following “grep” command with –v option will search those lines of customers.txt file that do not contain the string, ‘Abir’. The lines of the file that does not contain the string ‘Abir’ will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. There are five lines in the customers.txt file that do not contain the string ‘Abir’, and these lines have been printed in the output:
Search String With Case Insensitive Match:
The “grep” command searches string from the file in a case-sensitive manner by default. The -i option of the “grep” command is used to search a string from a file in a case-insensitive manner. In this example, the “grep” command with the -i option has been used to search a particular string in a case-insensitive way from the customers.txt file that was created before.
The following command will display the content of the customers.txt file:
The following “grep” command with the –i option will search those lines of the customers.txt file that contain the string, ‘minhaz’. If one or more lines exist in the file with the string where the letter can be capital or small, that line will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the fourth line of the text file contains the word ‘Minhaz’ that matches the word ‘minhaz’ if the strings are compared in a case-insensitive manner. So, the fourth line of the file has printed in the output by highlighting the searching string.

Search the Whole Word Only:
The -w option of the “grep” command is used to search a whole word from a file in a case-sensitive manner. In this example, the “grep” command with the -w option has been used to search a whole word from the customers.txt file that is created in the first example.
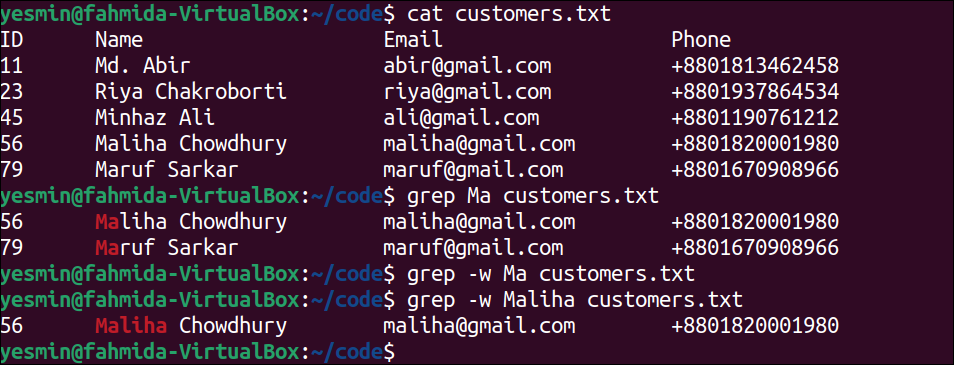
The following command will display the content of the customers.txt file:
The following “grep” command will search those lines of the text file that contain the string ‘Ma’. If any line of the file contains the string, ‘Ma’, then that line will be printed:
The following “grep” command will search those lines of the text file that contain the word ‘Ma’ exactly. If any line of the file contains the word ‘Ma’ exactly, then that line will be printed:
The following “grep” command will search those lines of the text file that contain the word ‘Maliha’ exactly. If any line of the file contains the word ‘Maliha’ exactly, then that line will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. The “grep” command with the –w option and the searching word ‘Ma’ returned nothing because the text file does not contain any word, ‘Ma’. The “grep” command with the –w option and the searching word ‘Maliha’ returned the fifth line of the file that contains the word, “Maliha”.
Search Multiple Files in the Current Directory:
The “grep” command is used to search particular content in a file and search multiple files in the current directory based on searching string or pattern. The way to search multiple files in the current directory using the “*” wildcard has shown in this example for the customers.txt file.
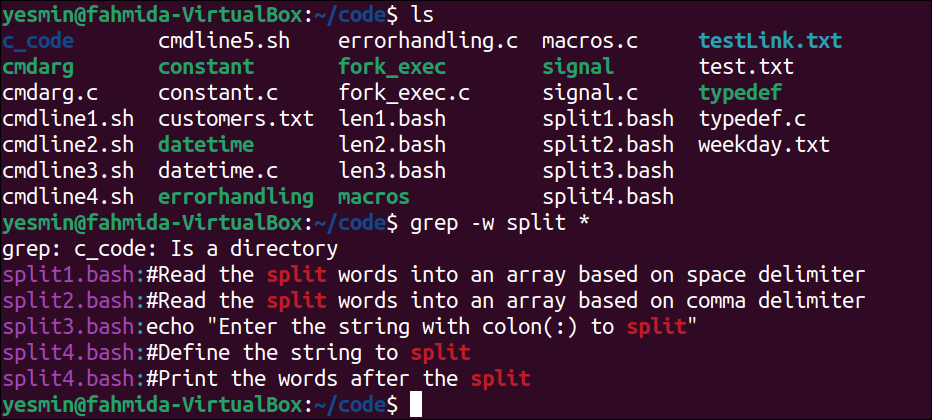
The following command will display all files and folders of the current directory:
The following “grep” command will search those files of the current directory that contain the word ‘split’. The list of filenames with the lines containing the word ‘split’ in the current directory will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, four files in the current directory contain the word ‘split’, and these are split1.bash, split2.bash, split3.bash, and split4.bash.
Search Recursively in a Directory:
The -r option is used with the “grep” command to search a particular string or pattern recursively in a directory. The use of the “grep” command to search recursively in the current directory is presented in this example for the customers.txt file.
The following command will display all files and folders of the current directory:
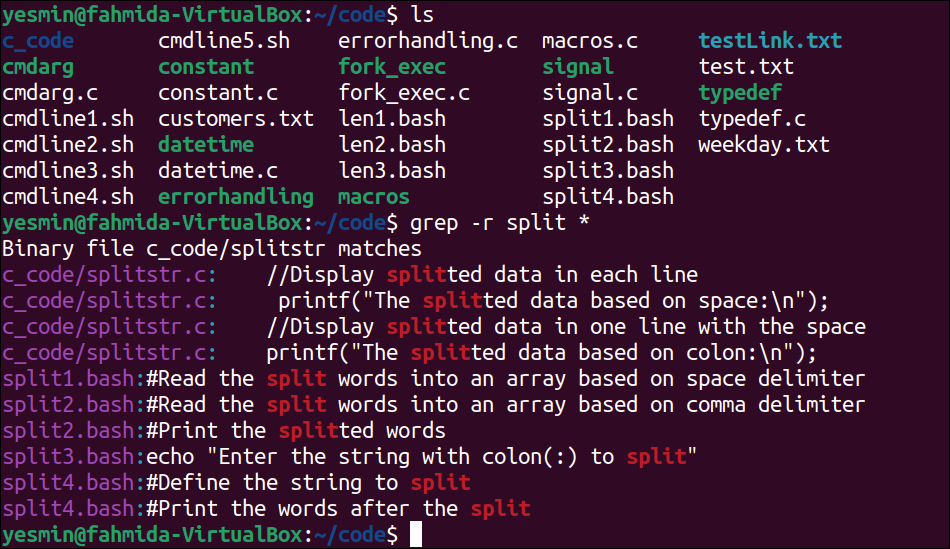
The following “grep” command will search those files of the current directory recursively that contain the word, ‘split’. The files of the current directory and the sub-directory that contain the word ‘split’ will be printed with the lines:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, five files in the current directory contain the word, ‘split’. The four files exist in the current directory, and these are split1.bash, split2.bash, split3.bash, and split4.bash. File 1 exists in the sub-directory, and that is splitstr.c.
Search Without Using Filename:
The -h or –no-filename option is used with the “grep” command to search a particular string or pattern without using a filename. This option is useful if there is only one file in the current directory. The way to search without using a filename is by the “grep” command is presented in this example.
The following command will display all files and folders of the current directory:
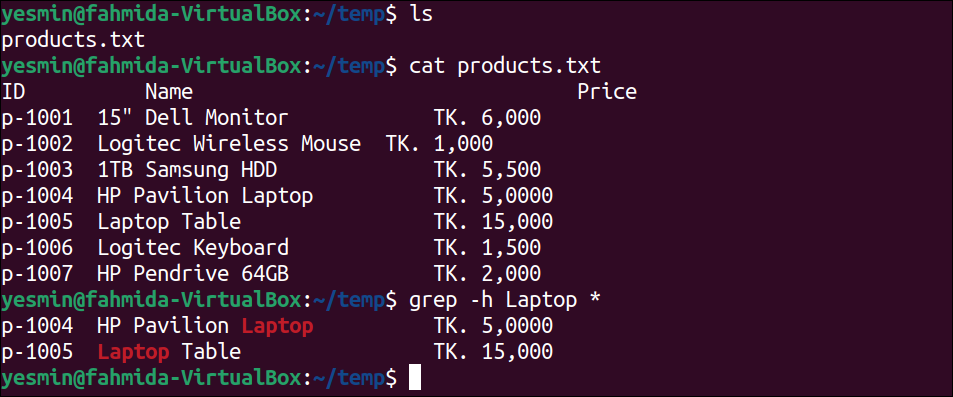
The following command will display the content of the products.txt file, which is the only file of the current directory and require to be created before executing the “grep” command:
The following “grep” command will search those lines of the products.txt file that contain the word, ‘Laptop’ and print those lines:
Output:
The following output will appear after executing the above commands from the terminal. The searching string ‘Laptop’ has been searched in the products.txt file. According to the output, the fifth and sixth lines of the products.txt file contain the word ‘Laptop’, and these lines have been printed by highlighting the matching string:
Add Line Number to the Output:
The -n option of the “grep” command is used to print the output of the search string with the line number of the file. In this example, the “grep” command with the -n option has been used to display the searching output with the line number of customers.txt file that is created in the first example.
The following command will display the content of the customers.txt file:
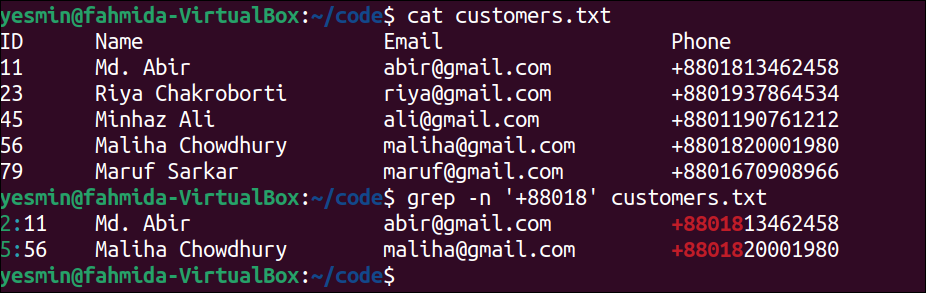
The following “grep” command will search and print those lines of the text file with the line number that contains the string, ‘+88018’. The lines of the file that contain the string ‘+88018’ will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the second and fifth lines of the customers.txt file contain the string ‘+88018’. So, these two lines have been printed with the line number by highlighting the matching string.
Use of Wildcard to Match Single Character:
The “.” wildcard character is used in the regular expression to match a single character. When all characters of the searching word are not known, then this character can be used to define the pattern of the “grep” command to search that particular word in the file. The use of this wildcard for a matching single character in the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search and print those lines of customers.txt file that contain the word with five characters and start with ‘Ma‘. Here, three dots (.) have been used in the pattern to denote three single characters:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the sixth line of the file contains the string, ‘Maruf’ that is five characters long and starts with ‘Ma’. So, the sixth line has been printed by highlighting the matching string. The fifth line of the file also contains the string that starts with ‘Ma’, but the length of the word is more than five characters. So, the fifth line has not been printed.

Use of Wildcard to Match Zero or More Times:
The * (asterisk) wildcard character is used with the “grep” command to match the string or pattern zero or more times. The use of this wildcard for matching any string for zero or more times is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
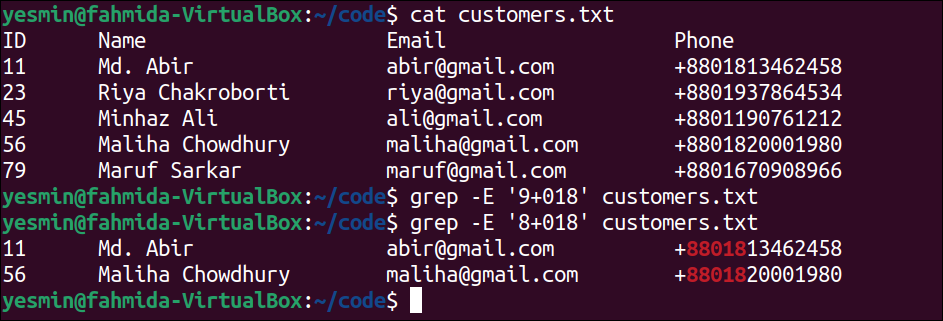
The following “grep” command will search those lines of the text file that contain the string ‘+880’ and any string that starts with ‘18’ after that string. The match can be found zero or more times. The lines of the file that match the pattern, ‘+880*18’ will be printed:
The following “grep” command will search those lines of the text file that contain the string ‘+880’ and any string that starts with ‘15’ after that string. The match can be found zero or more times like before. The lines of the file that match the pattern, ‘+880*15’ will be printed:
Output:
The following output will appear after executing the above commands from the terminal. According to the output, two lines of the file have matched with the pattern, ‘+880*18’ of the first “grep” command, and these lines have been printed by highlighting the matching number, ‘88018’. No line of the file has matched with the pattern ‘+880*15’ and the empty output is generated for the second “grep” command:
Use of Wildcard to Match the Exact Number of Times:
The second brackets {} with n number is used in the pattern to match a particular string in a file for the exact number of times. The use of the second brackets {} with a number in a pattern is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will search those lines of the text file that contain exactly the number of two digits within the number 1 to 5. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. The second, third, and fourth lines of the text file contain 11, 13, 24, 23, 45, 34, and 12. Those are within the range of 1 to 5. These lines have been printed in the output by highlighting the matching numbers.
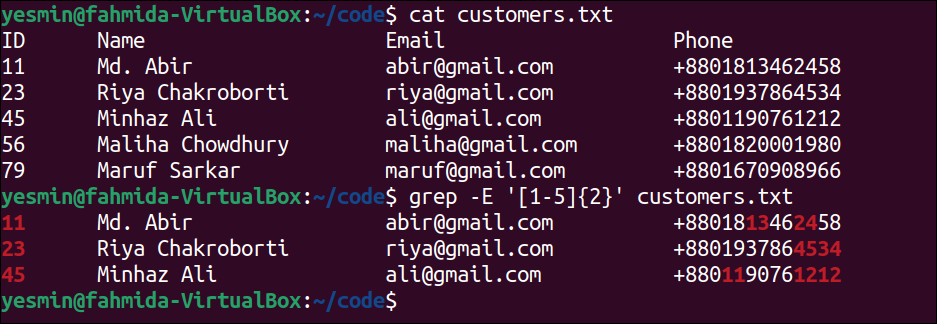
Print the Particular Number of Lines After the Matching Lines:
The -A or –after-context with a numeric value is used to print the particular number of lines after the matching string or pattern found in the file. The use of –A option of “grep” command is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will display the lines of the customers.txt file that contain the string ‘Riya’ and the next two lines after the matching line. No output will generate if no line of the file matches with the string, ‘Riya’:
Output:
The following output will appear after executing the previous commands from the terminal. The string ‘Riya’ exists in the third line of the file. The fourth and fifth lines are the next two lines of the matching line. So, the third, fourth, and fifth lines have been printed in the output by highlighting the matching string.
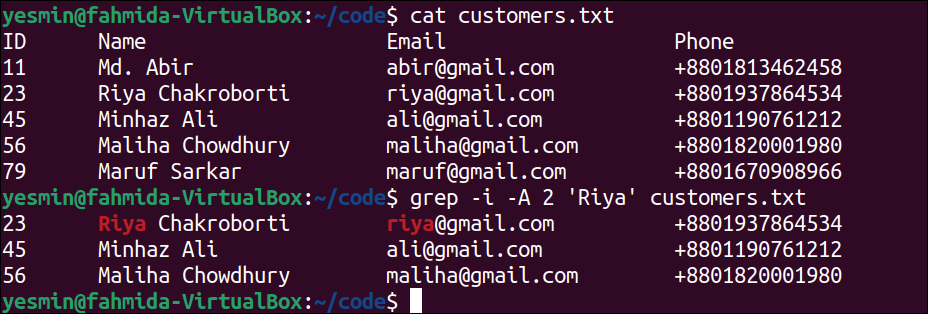
Print the Particular Number of Lines Before the Matching Lines:
The -B or –before-context with a numeric value is used to print the particular number of lines before the matching string or pattern found in the file. The use of the –B option of the “grep” command is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will display the line that contains the string ‘Riya’ and one line before the matching line. No output will generate if no line of the file matches with the string, ‘Riya’:
Output:
The following output will appear after executing the previous commands from the terminal. The string ‘Riya’ exists in the third line of the file. The second line is the previous line of the matching line. So, the second and third lines have been printed in the output by highlighting the matching string.

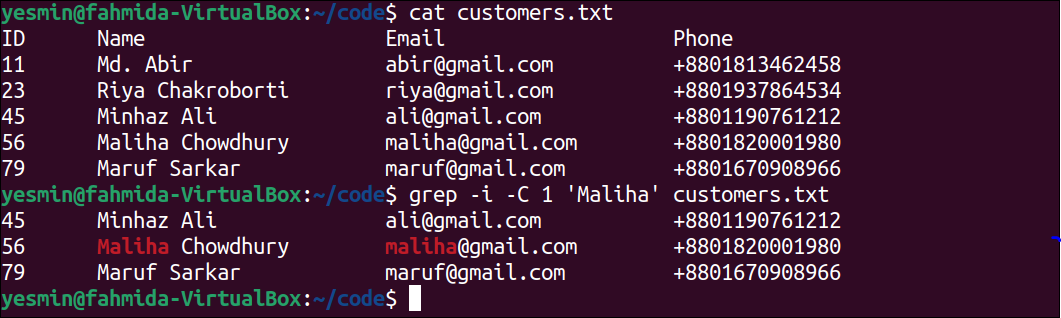
Print the Particular Number of Lines After and Before the Matching Lines:
The -C option with a numeric value is used to print the particular number of lines before and after the matching string or pattern found in the file. The use of the –C option of the “grep” command, is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will display the line that contains the string ‘Maliha’, one line before the matching line and one line after the matching line. No output will generate if no line of the file matches with the string, ‘Maliha’.
Output:
The following output will appear after executing the previous commands from the terminal. The fifth line contains the string, ‘Maliha’. The fourth line is the previous line of the matching line, and the sixth line is the following line of the matching line. So, the fourth, fifth, and sixth lines have been printed in the output by highlighting the matching string.
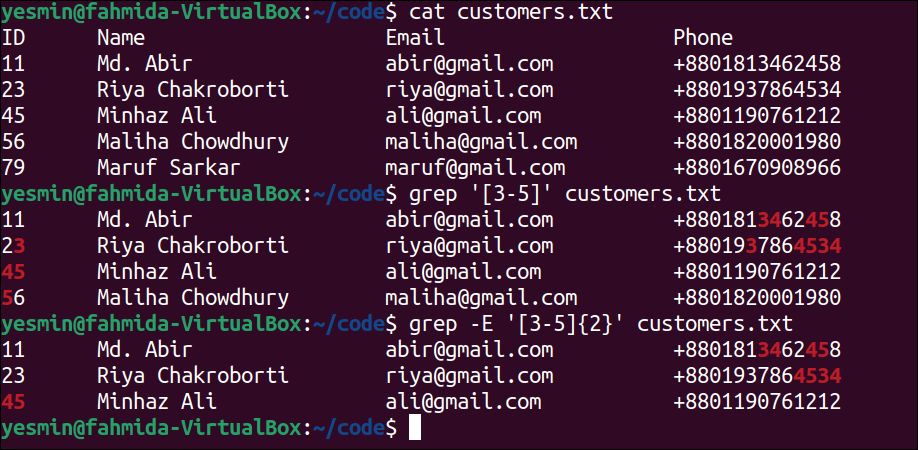
Match Specific Digits Using Third Brackets []:
The range of specific digits can be defined in the regular expression pattern of the “grep” command by using third brackets []. The way to search specific digits using the “grep” command in the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search the lines of the text file that contain the digits of the range 3 to 5. The lines of the file that match the pattern will be printed:
The following “grep” command will search those lines of the text file that contain two digits of the range of 3 to 5. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. The first “grep” command matches with the second, third, fourth, and fifth lines of the text file for the digits 3, 4, and 5 highlighted in the output. The second “grep” command matches with the second, third, and fourth lines of the text file for two-digit numbers containing 3, 4, and 5 highlighted in the output.
Match a Pattern With Specific Characters Using Third Brackets []:
The specific characters of a file can match in different ways by using third brackets. The range of characters or the specific characters can be used in the regular expression pattern by using third brackets to search particular lines from the file. The way to search specific characters in the customers.txt file by using the pattern of range of characters or specific characters is presented in this example.
The following command will display the content of the customers.txt file:
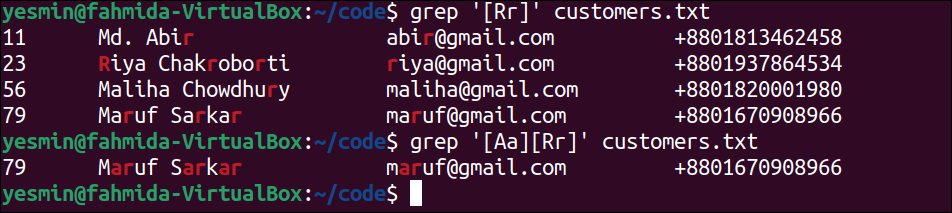
The following “grep” command will search those lines that contain the string starts with ‘Ma’ and any characters of the range a to r. The lines of the file that match this pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the regular expression used in the “grep” command, the fifth and sixth lines of the text file have matched, and these lines have been printed in the output. These lines contain the string, ‘Ma‘, and the next character of this string is ‘l‘ and ‘r‘, which are in the range [a-r].
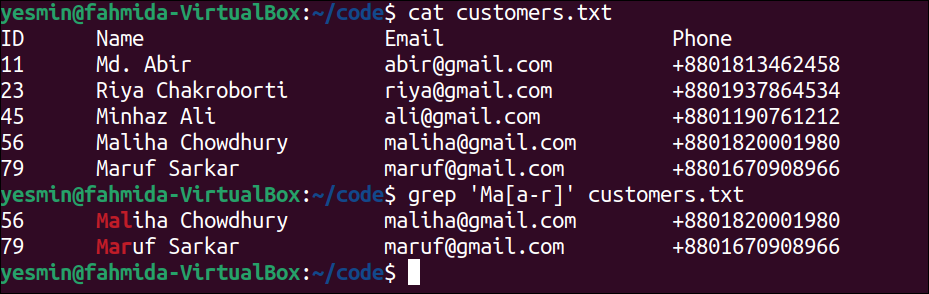
The following “grep” command will search those lines of the text file that contain the character ‘R’ or ‘r’. The lines of the file that match this pattern will be printed:
The following “grep” command will search those lines of the text file that contain the strings ‘AR’ or ‘Ar’ or ‘aR’ or ‘ar’. The lines of the file that match this pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. The pattern of the first “grep” command has matched with the second, third, fifth, and sixth lines of the text file, and those lines have been printed in the output. The pattern of the second “grep” command has matched with the sixth line of the text file, and that line has been printed in the output.
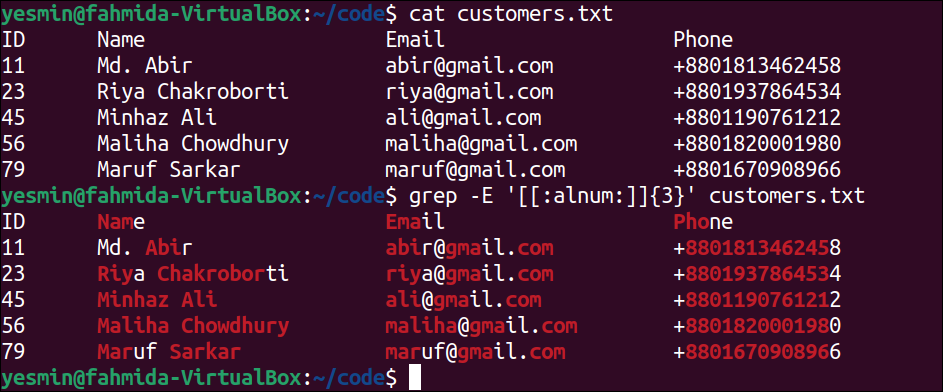
Match Alphabetic and Numeric Characters Using [:alnum:] Class:
The [:alnum:] class is used in the regular expression pattern to match alphabetic and numeric characters. It is equivalent to the pattern, [A-z0-9]. The way to use this class as a pattern of the “grep” command to search all alphabetic and numeric characters of the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search any alphabet and number of three characters in the customers.txt file. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the file content, all lines contain the alphabet or number of three characters. The matching alphabets and numbers are highlighted in the output by omitting the special characters, non-matching alphabetic, and numeric characters.
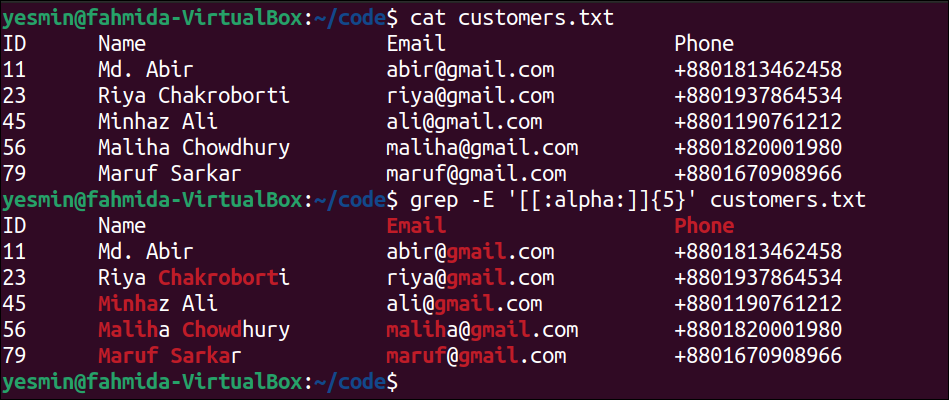
Match Alphabetic Characters Using [:alpha:] Class:
The [:alpha:] class is used in the regular expression pattern to match the alphabetic characters only. It is equivalent to the pattern, [A-z]. The way to use this class as a pattern of the “grep” command to search all alphabetic characters of the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search any alphabetic characters of five characters in the customers.txt file. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the file content, all the lines that contain the alphabets of five characters and the matching alphabets are highlighted in the output by omitting digits, non-matching characters, and special characters.
Match Numeric Characters Using [:digit:] Class:
The [:digit:] class is used in the regular expression pattern to match the numeric characters only. It is equivalent to the pattern [0-9]. The way to use this class as a pattern of the “grep” command to search all numeric characters of the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search all numeric characters in the customers.txt file. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. In the file content, all the lines containing digits and matching digits are highlighted in the output by omitting all alphabets and special characters.

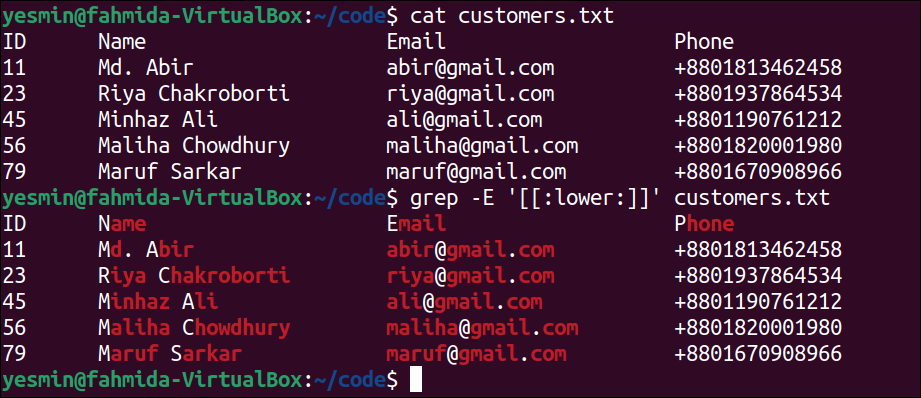
Match Lowercase Characters Using [:lower:] Class:
The [:lower:] class is used in the regular expression pattern to match all lowercase characters only. It is equivalent to the pattern, [a-z]. The way to use this class as a pattern of the “grep” command to search all lowercase characters of the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search all lowercase characters in the customers.txt file. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the file content, all lines contain lowercase characters. So, all the lines of the file have been printed, and the matching lowercase characters are highlighted in the output by omitting the digits, uppercase letter, and special characters.
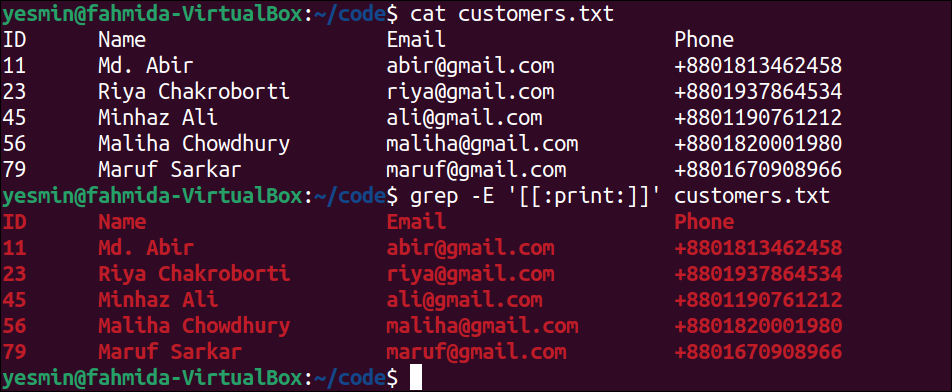
Match Printable Characters Using [:print:] Class:
The [:print:] class is used in the regular expression pattern to match printable characters. The way to use this class as a pattern of the “grep” command to search all printable characters of the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search all printable characters in the customers.txt file. The lines of the file that matches the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, all characters of the customers.txt file are printable characters. So, all lines of the file have been printed, and all characters have been highlighted in the output.
Match Space Character Using [:space:] Class:
The [:space:] class is used in the regular expression pattern to match those lines that contain the space characters. This class can be used in the pattern of the “grep” command to search the lines of the file that contain the space characters. Create a text file named demo.txt with the following content to check the use of the [:space:] class. Here, the second line of the file contains space characters:
demo.txt
Welcome To LinuxHint
The following command will display the content of the demo.txt file:
The following “grep” command will search those lines of the demo.txt file that contain space. The lines of the file that contain space will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. Only one line of the text file contains space that has been printed in the output. The first line of the file has not been printed because there is no space in the line. The second line of the file is printed because there are two spaces in the line.

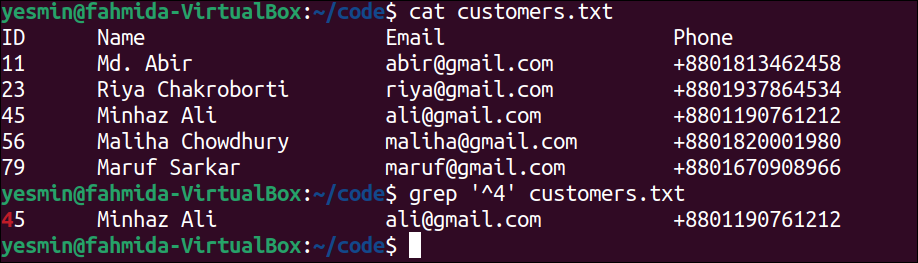
Match From the Beginning of the Line:
The caret (^) symbol is used in the regular expression to match the line starting with the particular character or string in a file. The use of this symbol is presented in this example for the customers.txt file that was created before.
The following command will display the content of the customers.txt file:
The following “grep” command will search those lines of customers.txt file that start with the number 4. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, only one line exists in the customers.txt file starts with ‘4‘. It is the fourth line of the file that has been printed in the output.
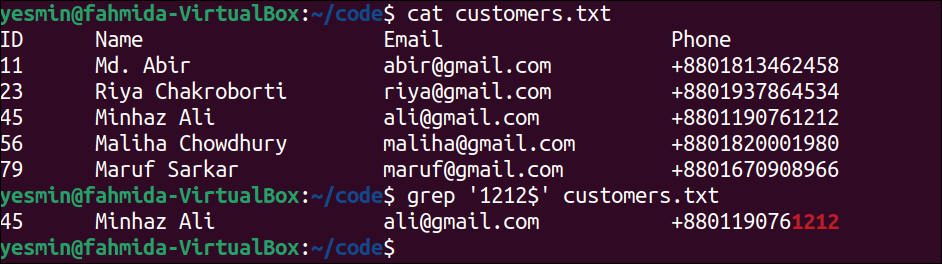
Match to End of the Line:
The dollar ($) symbol is used in the regular expression to match the line end with the particular character or string in a file. The use of this symbol is presented in this example for the customers.txt file that was created before.
The following command will display the content of the customers.txt file:
The following “grep” command will search those lines of customers.txt file that end with the string, ‘1212’. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, there is only one line that exists in the customers.txt file ending with ‘1212‘. It is the fourth line of the file that has been printed in the output.
Match With Concatenation:
The regular expression pattern can be created by concatenating multiple patterns. The dot (.) is used to concatenate the patterns. The use of concatenated with the “grep” command is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will search those lines of customers.txt file that contain the word starts with ‘M’ or ‘R’ and ends with ‘K’ or ‘k’. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, two lines exist in the customers.txt file that start with ‘R‘ and ‘M‘, and end with ‘k‘. So, the third and sixth lines of the file have been printed in the output.
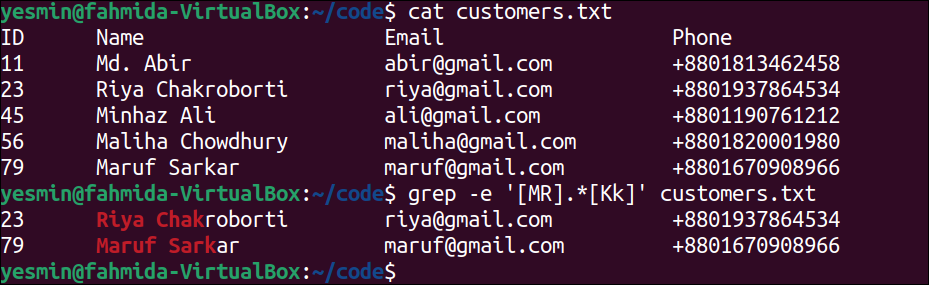
Match With Alternation:
The “grep” command supports multiple patterns. The alternation or OR (|) operation is used in the pattern of the “grep” command to define multiple patterns. Different possible matches can be defined in the pattern by using alternation that works like logical OR operator. The use of the alternation in the “grep” pattern to search the specified string in the customers.txt file is presented in this example.
The following command will display the content of the customers.txt file:
The following “grep” command will search the string ‘Riya‘ or ‘Minhaz‘ in the customers.txt file. Here, the backslash(\) has been used with pipe (|) to do the task of an alternation. The lines of the file that match the pattern will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. The string, ‘Riya‘ exists in the third line of the file, and the string, ‘Minhaz‘ exists in the fourth line of the file. These lines have been printed in the output.
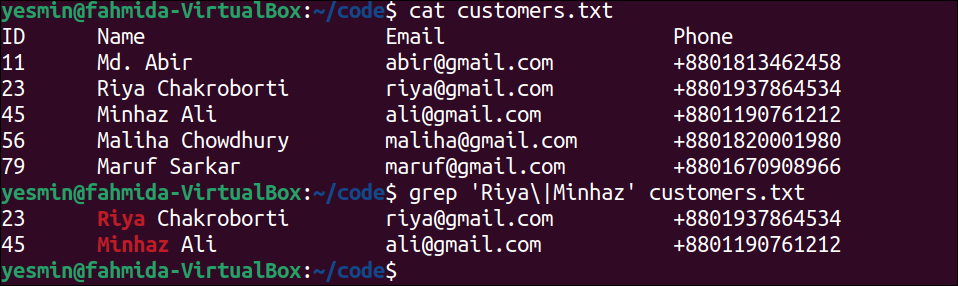
Match With Back-References:
The way to remember the previous match of any pattern is called back-references. The “grep” command supports the features of back-references. It can be created by enclosing the part of the pattern using parenthesis and using \1 for the first reference, \2 for the second reference, and so on. The use of back-reference in the “grep” command is presented in this example for the customers.txt file.
The following command will display the content of the customers.txt file:
The following “grep” command will search any digits from the range of 0 to 5 in the customers.txt file. It will keep the reference if any match is found and use the back-reference to match with the remaining part of the file. The matching line will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the second line of the file has matched the digits, 11 used as a back-reference. The fourth and fifth lines of the file have matched based on the back-reference.
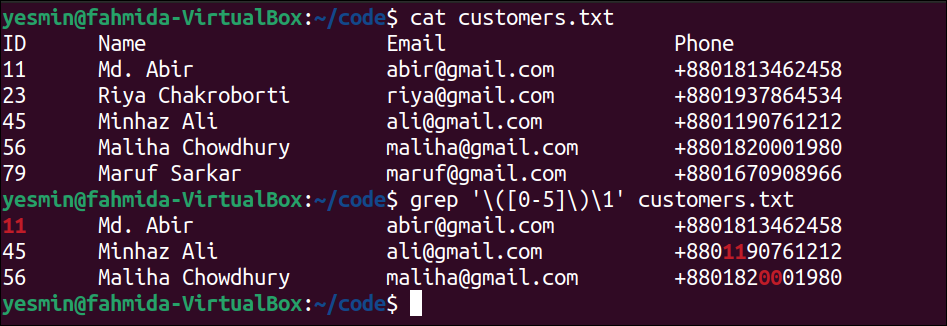
Combine “grep” With the “ps” Command Using a Pipe:
Multiple processes can be executed simultaneously in the Linux operating system. The full form of the “ps” command is ‘process status‘. The main task of this command is to check the status of all running processes and display different information about the processes. This command is very useful for administrative tasks. The way to use the “grep” command on the output of the “ps” command is shown in this example.
The following command will display the information of all running processes:
The following command will search the lines that end with ‘bash’ in the output of the “ps” command. If the content of any line of the “ps” output will match with the pattern used in the “grep” command, then that line will be printed:
Output:
The following output will appear after executing the previous commands from the terminal. According to the output, the second line of the output of the “ps” command matched with the pattern of the “grep” command, and it has been printed.
Combine “grep” With the “awk” Command to Print Specific Fields:
The “awk” command is another way to search content in a file based on any pattern. Different tasks can be done by using the “awk” command when the pattern matches with any text or the file line, such as matching pattern, formatting output, string operation, etc. The way to format the output of the “grep” command using the “awk” command is presented in this example.
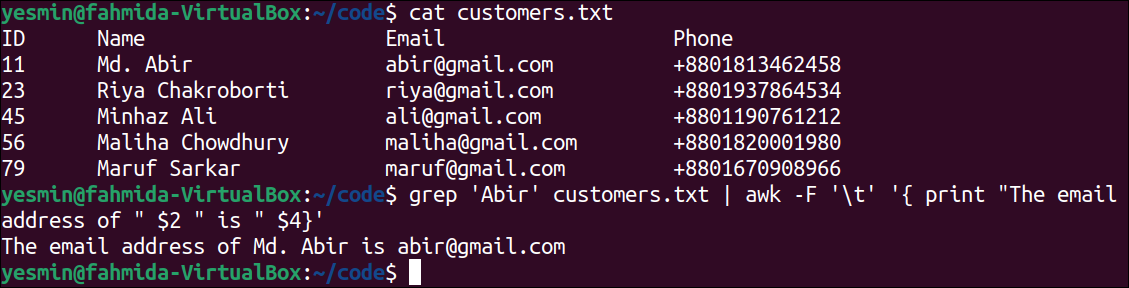
The following command will display the content of the customers.txt file:
The following command will search the string, ‘Abir’ in the customers.txt file and send the output to the “awk” command that will print the formatted output from the matching line:
Output:
The following output will appear after executing the previous commands from the terminal. The word ‘Abir’ exists in the second line of the customers.txt file. So, the value of the second and fourth columns of that line is separated by ‘\t‘, and it has been printed with other strings by using the “awk” command.
Conclusion:
The content of a file or multiple files can be searched in different ways in Linux by using the “grep” command. The system administrator uses this command to perform various types of administrative tasks. It has many options to perform searching in a file or a directory in different ways. The most commonly used basic and extended regular expression patterns for searching content in a file have been discussed in this tutorial. I hope the purposes of using this command will be cleared for the Linux users by practicing the 30 grep examples shown here and using this command properly.